你有特斯拉我有树莓派,手工打造车牌识别检测系统,家用车变智能车
文章来源:未知
作者:老客SEO
人气:19
 2020-03-15 22:19:03
2020-03-15 22:19:03
怎样在不换车的前提下打造一个智能车系统呢?一段时间以来,本文作者 Robert Lucian Chiriac 一直在思考让车拥有探测和识别物体的能力。这个想法非常有意思,因为我们已经见识过特斯拉的能力,虽然没法马上买一辆特斯拉(不得不提一下,Model 3 现在看起来越来越有吸引力了),但他有了一个主意,可以努力实现这一梦想。
所以,作者用树莓派做到了,它放到车上可以实时检测车牌。

在接下来的内容里,我们将介绍项目中的每个步骤,并提供 GitHub 项目地址,其中项目地址只是客户端工具,还其它数据集与预训练模型都可以在原博客结尾处找到。
项目地址:
https://github.com/RobertLucian/cortex-license-plate-reader-client
下面,让我们看看作者 Robert Lucian Chiriac 是如何一步步打造一个好用的车载检测识别系统。
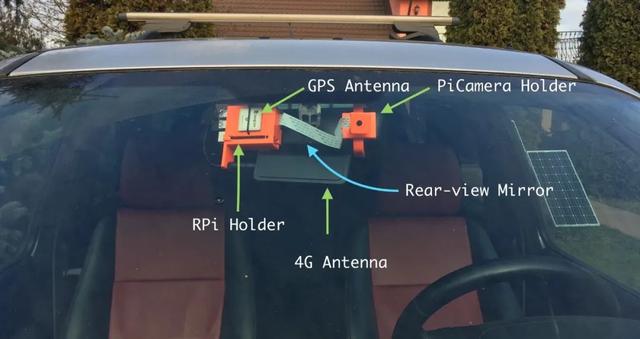
放一张成品图镇楼。
第一步:确定项目范围
开始之前,我脑海里出现的第一个问题是这样一个系统应该能够做到什么。如果说我活到现在学到了什么,那就是循序渐进——从小处着手永远是最好的策略。所以,除了基本的视觉任务,我需要的只是在开车时能清楚地识别车牌。这个识别过程包括两个步骤:
- 检测到车牌。
- 识别每个车牌边界框内的文本。
我觉得如果我能完成这些任务,再做其他类似的任务(如确定碰撞风险、距离等)就会容易得多。我甚至可能可以创建一个向量空间来表示周围的环境——想想都觉得酷。
在确定这些细节之前,我知道我得先做到:
- 一个机器学习模型,以未标记的图像作为输入,从而检测到车牌;
- 某种硬件。简单地说,我需要连接了一个或多个摄像头的计算机系统来调用我的模型。
那就先从第一件事开始吧——构建对象检测模型。
第二步:选择正确的模型
经过仔细研究,我决定用这些机器学习模型:
- YOLOv3- 这是当下最快的模型之一,而且跟其他 SOTA 模型的 mAP 相当。我们用这个模型来检测物体;
- CRAFT 文本检测器 - 我们用它来检测图像中的文本;
- CRNN - 简单来说,它就是一个循环卷积神经网络模型。为了将检测到的字符按照正确的顺序排成单词,它必须是时序数据;
这三个模型是怎么通力合作的呢?下面说的就是操作流程了:
- 首先,YOLOv3 模型从摄像机处接收到一帧帧图像,然后在每个帧中找到车牌的边界框。这里不建议使用非常精确的预测边界框——边界框比实际检测对象大一些会更好。如果太挤,可能会影响到后续进程的性能;
- 文本检测器接收 YOLOv3 裁剪过的车牌。这时,如果边界框太小,那么很有可能车牌文本的一部分也被裁掉了,这样预测结果会惨不忍睹。但是当边界框变大时,我们可以让 CRAFT 模型检测字母的位置,这样每个字母的位置就可以非常精确;
- 最后,我们可以将每个单词的边界框从 CRAFT 传递到 CRNN 模型,以预测处实际单词。
有了我的基本模型架构草图,我可以开始转战硬件了。
第三步:设计硬件
当我发现我需要的是一种低功耗的硬件时,我想起了我的旧爱:树莓派。因为它有专属相机 Pi Camera,也有足够的计算能力在不错的帧率下预处理各个帧。Pi Camera 是树莓派(Raspberry Pi)的实体摄像机,而且有其成熟完整的库。
为了接入互联网,我可以通过 EC25-E 的 4G 接入,我以前的一个项目里也用过它的一个 GPS 模块,详情可见:
博客地址:https://www.robertlucian.com/2018/08/29/mobile-network-access-rpi/
然后我要开始设计外壳了——把它挂在汽车的后视镜上应该没问题,所以我最终设计了一个分为两部分的支撑结构:
- 在后视镜的方向上,树莓派+ GPS 模块+ 4G 模块将保留下来。关于我使用的 GPS 和 4G 天线,你可以去看一下我关于 EC25-E 模块的文章;
- 在另一侧,我用一个利用球关节活动的手臂来支撑 Pi Camera
我会用我可靠的 Prusa i3 MK3S 3D 打印机来打印这些零件,在原文文末也提供了 3D 打印参数。
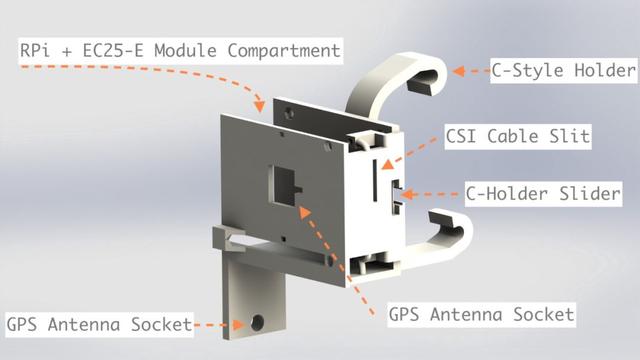
图 1 :树莓派+4G/GPS 壳的外形
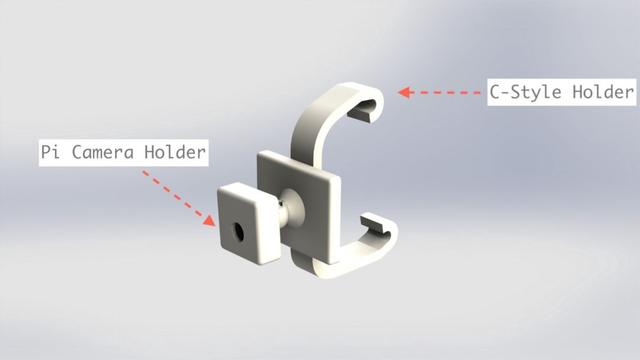
图 2:利用球关节活动臂支撑 Pi Camera
图 1 和图 2 就是它们渲染时候的样子。注意这里的 c 型支架是可插拔的,所以树莓派的附件和 Pi Camera 的支撑物没有和支架一起打印出来。他们共享一个插座,插座上插着支架。如果某位读者想要复现这个项目,这是非常有用的。他们只需要调整后视镜上的支架就可以了。目前,这个底座在我的车(路虎 Freelander)上工作得很好。

图 3:Pi Camera 支撑结构的侧视图
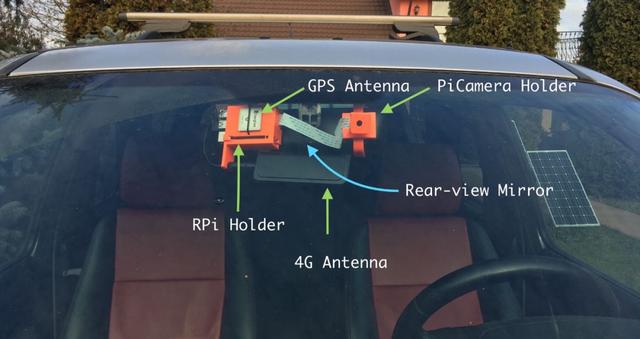
图 4:Pi Camera 支撑结构和 RPi 底座的正视图
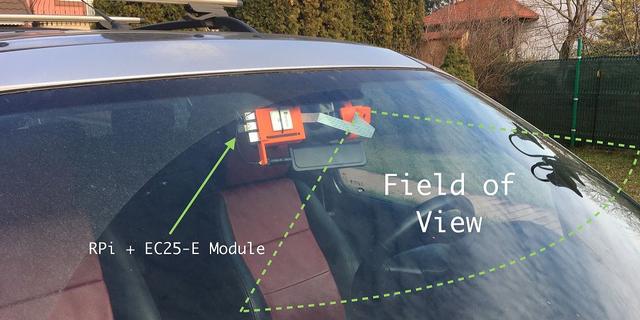
图 5:预计的相机视野

图 6:内置 4G/GPS 模块、Pi Camera,树莓派的嵌入式系统近照
显然,这些东西需要一些时间来建模,我需要做几次才能得到坚固的结构。我使用的 PETG 材料每层高度为 200 微米。PETG 在 80-90 摄氏度下可以很好地工作,并且对紫外线辐射的抵抗力很强——虽然没有 ASA 好,但是也很强。
这是在 SolidWorks 中设计的,所以我所有的 SLDPRT/SLDASM 文件以及所有的 STLs 和 gcode 都可以在原文末找到。你也可以用这些东西来打印你自己的版本。
第四步:训练模型
既然硬件解决了,就该开始训练模型了。大家应该都知道,尽可能站在巨人的肩膀上工作。这就是迁移学习的核心内容了——先用非常大的数据集来学习,然后再利用这里面学到的知识。
YOLOv3
我在网上找了很多预先训练过的车牌模型,并没有我最初预期的那么多,但我找到了一个在 3600 张车牌图上训练过的。这个训练集并不大,但也比什么都没有强。除此之外,它也是在 Darknet 的预训练模型的基础上进行训练的,所以我可以直接用。
模型地址:https://github.com/ThorPham/License-plate-detection
因为我已经有了一个可以记录的硬件系统,所以我决定用我的系统在镇上转上几个小时,收集新的视频帧数据来对前面的模型进行微调。
我使用 VOTT 来对那些含有车牌的帧进行标注,最终创建了一个包含 534 张图像的小数据集,这些图像中的车牌都有标记好的边界框。
数据集地址:https://github.com/RobertLucian/license-plate-dataset
然后我又找到利用 Keras 实现 YOLOv3 网络的代码,并用它来训练我的数据集,然后将我的模型提交到这个 repo,这样别人也能用它。我最终在测试集上得到的 mAP 是 90%,考虑到我的数据集非常小,这个结果已经很好了。
- Keras 实现:https://github.com/experiencor/keras-yolo3
- 提交合并请求:https://github.com/experiencor/keras-yolo3/pull/244
CRAFT & CRNN
为了找到一个合适的网络来识别文本,我经过了无数次的尝试。最后我偶然发现了 keras-ocr,它打包了 CRAFT 和 CRNN,非常灵活,而且有预训练过的模型,这太棒了。我决定不对模型进行微调,让它们保持原样。
keras-ocr 地址:https://github.com/faustomorales/keras-ocr
最重要的是,用 keras-ocr 预测文本非常简单。基本上就是几行代码。你可以去该项目主页看看这是如何做到的。
第五步:部署我的车牌检测模型
模型部署主要有两种方法:
- 在本地进行所有的推理;
- 在云中进行推理。
这两种方法都有其挑战。第一个意味着有一个中心「大脑」计算机系统,这很复杂,而且很贵。第二个面临的则是延迟和基础设施方面的挑战,特别是使用 gpu 进行推理。
在我的研究中,我偶然发现了一个名为 cortex 的开源项目。它是 AI 领域的新人,但作为 AI 开发工具的下一个发展方向,这无疑是有意义的。
cortex 项目地址:https://github.com/cortexlabs/cortex
基本上,cortex 是一个将机器学习模型部署为生产网络服务的平台。这意味着我可以专注于我的应用程序,而把其余的事情留给 cortex 去处理。它在 AWS 上完成所有准备工作,而我唯一需要做的就是使用模板模型来编写预测器。更棒的是,我只需为每个模型编写几十行代码。
如下是从 GitHub repo 获取的 cortex 运行时的终端。如果这都称不上优美简洁,那我就不知道该用什么词来形容它了:

因为这个计算机视觉系统不是为了实现自动驾驶而设计的,所以延迟对我来说不那么重要,我可以用 cortex 来解决这个问题。如果它是自动驾驶系统的一部分,那么使用云提供商提供的服务就不是一个好主意,至少现在不是。
部署带有 cortex 的 ML 模型只需:
- 定义 cortex.yaml 文件,它是我们的 api 的配置文件。每个 API 将处理一种类型的任务。我给 yolov3 的 API 分配的任务是检测给定帧上的车牌边界框,而 crnn API 则是在 CRAFT 文本检测器和 crnn 的帮助下预测车牌号码;
- 定义每个 API 的预测器。基本上你要做的就是在 cortex 中定义一个特定类的 predict 方法来接收一个有效负载(所有的 servy part 都已经被平台解决了),这个有效负载来可以来预测结果,然后返回预测结果。就这么简单!
这里有一个经典 iris 数据集的预测器示例,但因为文章篇幅原因,具体细节在此就不做赘述了。项目链接里可以找到 cortex 使用这两个 api 的方法——这个项目的所有其他资源都在本文的最后。





