巴别塔风云:百度ERNIE 2.0折射出的产业奇点
文章来源:未知
作者:老客SEO
人气:15
 2019-08-03 12:40:13
2019-08-03 12:40:13
这两天AI圈有一个广受关注的新闻,百度发布了持续学习的语义理解框架ERNIE 2.0,这个模型在1.0版本中文任务中全面超越BERT的基础上,英文任务取得了全新突破,在共计16个中英文任务上超越了BERT和XLNet, 取得了SOTA效果。
可能对于大部分AI技术的关注者与AI开发者来说,ERNIE 2.0最直接的价值在于业界又将获得一个效果强劲的NLP模型,同时也是中国AI技术又一次令人兴奋的成果。
成绩之外,ERNIE 2.0背后蕴藏的产业价值同样不容忽视。尤其是在目前国际贸易与科技背景下,ERNIE 2.0代表的无监督预训练语言模型正处在非常关键的产业位置。
ERNIE 2.0与BERT、XLNet的巅峰对决背后,是一场全球NLP产业格局的变幻与交锋。
NLP的提速换挡时代
让我们先把时间向前倒回一点,看看BERT和ERNIE这对《芝麻街》的里的朋友,为什么变成了整个AI行业关注的明星。

NLP,即自然语言处理,是AI领域极其重要的一条技术路径。它关乎于智能体如何理解人类的语言与文字,并在理解基础上人机智能交互。这个领域的重要性显而易见,而令业界兴奋的是,去年年底到今天,NLP技术在全球范围内掀起了一场“提速竞赛”。
去年10月,谷歌发布了被认为具备里程碑意义的NLP模型BERT。这种模型采用极大数据集上进行预训练的模式,一举刷新了AI在大量NLP数据集的最高分数。甚至在机器阅读理解等任务中,展现出了与人类不相上下的表现。
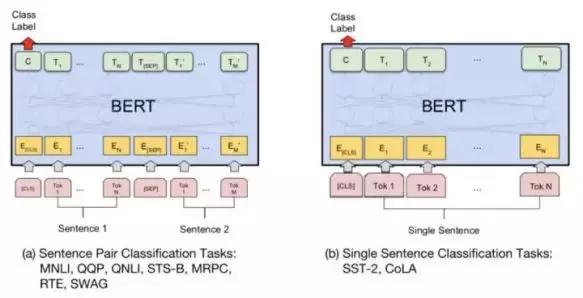
被AI业内人士称为“残暴到不留活路”的BERT,可以说将NLP提升到了新的轨道。另一个好消息,是BERT并没有就此进入一统江湖模式。今年3月,百度发布了基于知识增强技术的NLP模型ERNIE,在多个中文NLP任务中超越了BERT;今年6月,谷歌和CMU提出的NLP模型XLNet在20多项测试中排行第一,性能全面超越BERT;而Facebook不久前优化过的新BERT,又拿回了不少属于自己的记录。
故事至此,无监督预训练语言NLP模型基本进入了“三国杀”时代,背后隐隐浮现着谷歌与百度,东西两大AI巨头的技术攀跃。
而从产业价值上看,基于大规模数据的无监督预训练语言模型你追我赶,不断刷新记录,给NLP技术应用到各行各业带来了全新的机遇。作为NLP问题的基础解法,这些模型让机器阅读理解、情绪识别、文本分类等任务都达到了新高度,语音助手、在线客服、智能金融、对话机器人等广泛领域都将从中受益。
或许我们可以将这10个月以来的NLP进化,理解为一场提速换挡。语言智能领域,刚刚经历了柴油换汽油的剧变,这是一个时代的划页。
在这个具有广袤想象力的NLP时代,ERNIE 2.0来了。
ERNIE 2.0一剑东来,巴别塔之战格局变幻
如上文所述,今天的NLP竞速,是顶级高手间相互刷新AI记录的一场游戏,颇有点紫禁之巅叶孤城大战西门吹雪的味道。而这场竞速,发生在人类语言智能的巴别塔之巅。
而刚刚发布的ERNIE 2.0实际上代表了这样一件事:这场巅峰之战中,百度夺得了赛事的主动权。
从3月发布ERNIE 1.0,经过短短几个月时间,百度就完成了ERNIE的再升级,发布了能够持续学习的语义理解框架ERNIE 2.0,以及基于框架的ERNIE 2.0预训练模型。
整体来看,ERNIE 2.0不仅完成了一次记录刷新表演,同时也解决了BERT长时间被产业界诟病的“大力出奇迹”问题。对算力和数据量的要求更少,让无监督预处理语言模型更加贴近产业现实。总体来看,ERNIE 2.0闪耀NLP舞台,有三大硬核能力:
1、更好的效果:ERNIE英文任务方面取得全新突破,在共计16个中英文任务上超越了BERT和XLNet, 取得了SOTA效果。在英文任务上,ERNIE 2.0在自然语言理解数据集GLUE的7个任务上击败了BERT和XLNet;中文任务中,ERNIE 2.0在包括阅读理解、情感分析、问答等不同类型的9个数据集上超越了BERT并刷新了SOTA。可以说在NLP领域的关键问题中,推动了业界的前沿探索与突破。


2、更小的数据:无监督预训练NLP模型,一直被业界认为是数据越多,效果越好,有种大力出奇迹的意味。然而ERNIE 2.0在充分借助百度PaddlePaddle(飞桨)多机分布式训练优势的情况下,利用 79亿tokens数据就完成了模型的训练,约等于四分之一的XLNet数据。
3、更少的算力:无监督预训练语言模型一大问题,在于算力消耗过大,训练时间过长,从而导致产业化困难。ERNIE 2.0在这一点上也有出色表现,其仅仅使用64张V100 ,约八分之一XLNet硬件算力就实现了效果,而且为开发人员定制自己的NLP模型提供了方案。
在优秀的数据表现背后,或许我们还应该注意到更加宏观的产业问题:ERNIE 2.0代表的,是这场国际瞩目的NLP竞速里,中国能量从未缺席。
AI不缺席:NLP之路上的中国能量
过去,我们总是认为中国在科技创新上是落后的,中国科技产业善于模仿和塑造应用,但在基础研究与突破上往往缺席。然而ERNIE 2.0却证明了,在AI之路上的关键技术、关键话题,中国AI可以第一时间参与进来,贡献自己的力量。中国科技在AI时代不再缺席。
ERNIE 2.0与BERT、XLNet的竞速发展中,可以看到三层中国能量正在产业中闪耀。百度AI正在带给世界AI产业以惊喜。
1、中国智慧:BERT最为人诟病的一点,是它用庞大数据集砸入模型,产生了简单粗暴有效的效果。但在算法层面却缺乏创新。而在ERNIE 2.0中,百度实现了可持续学习语义理解能量。通过支持增量引入词汇(lexical)、语法 (syntactic) 、语义 (semantic) 等3个层次的自定义预训练任务,能够全面捕捉训练语料中的词法、语法、语义等潜在信息。这些任务通过多任务学习对模型进行训练更新,每当引入新任务时,就可在学习该任务的同时,不遗忘之前学到过的信息。
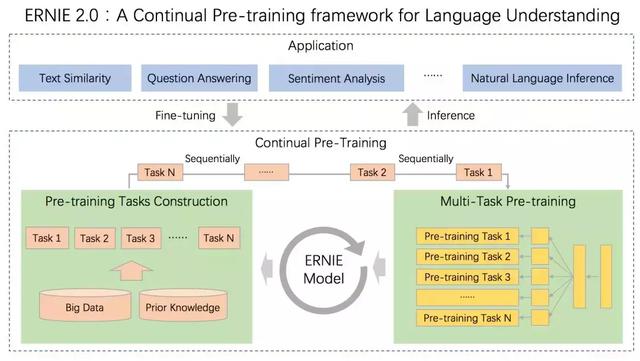
(ERNIE 2.0:可持续学习语义理解框架)
这意味着,ERNIE 2.0可以通过持续构建训练包含词法、句法、语义等预训练任务,持续提升模型效果。也就是说,ERNIE 2.0通过语言学与AI科学的跨领域结合,完成了算法逻辑上的大量创新,并验证了可持续学习语义理解的任务表现。这给AI行业开启了一条新的道路,为NLP领域打开了新的发展轨迹。这条中国智慧的贡献,恰好作用于AI界聚焦的前沿探索中,为全球AI技术提升贡献了独特力量。
2、中国位置:NLP的产业应用正在飞速发展,无监督预训练语言模型被认为在各类NLP应用中处于骨干网络的地位,是构成下一代NLP技术的底层。如果这个位置被BERT完全卡住,或者说被欧美公司完全卡住,那么很容易又会出现底层科技卡脖子问题。另一方面,BERT等模型并不精于中文任务,长期下去NLP领域英文应用可能大幅度领先中文应用,影响产业进程。这都是我们不愿意看到的。
ERNIE 2.0则证明,在这场底层技术角逐中,中国位置已经确立。中国科技在百度AI的全力以赴下,成为了领导者和探索者。
3、中国速度:去年评选全世界最受重视的AI新技术时,BERT和图网络占据前二。这不难看出全球科技产业对BERT的重视。然而几个月过去,中国已经有了可以媲美甚至领先BERT的NLP模型。这也是AI时代中国速度的一个体现。
ERNIE 2.0可以作为一个横轴,从中可以证明基础算法这个AI最核心领域,中国已经逐渐跟上了美国的速度,并且可以超越欧美顶级AI公司的算法。反向输出核心算法,用中国速度领跑AI。百度的AI硬核实力,可以看出正在呈现不断加速的特征。今年谷歌大会上,已经被外界评论为算法创新上的疲软。然而百度却接住了这个难题,逆势而上。中国AI速度,正在百度抛向世界的一个个算法中展现出来。

必须承认的是,今天的AI赛场上,中国能量已经不可忽视。这条路并非朝夕铺就,而是经过无数中国AI人的努力凝结而成。比如在刚结束的ACL上,百度共有10篇论文被大会收录,研究领域涵盖了多个NLP领域的热点话题与前沿方向,展现出了国际顶级水准的技术积淀。
而在学术与产业的不断突破背后,是百度从2010年起就加速发展NLP事业,在AI技术尚未被世界热捧的时候,就潜心NLP的前沿技术研究与产业应用。为业内培养了大量AI人才,成为国际顶级研究机构的百度NLP部门,在AI界素有“铁军”的美誉。目前,百度大脑语言与知识技术拥有最大的多元语义知识图谱以及最好的中文语义表示模型,目前可提供30+项技术工具,囊括了文本审核、机器翻译、语言生成等多项能力,面向业界提供多样、灵活、可定制的服务与场景解决方案。
由此可见,今天的成果,背后是十年磨一剑的技术探索与人才培养。一剑东来的百度,背后凝结了十年面壁图破壁的NLP苦功。其实,每次中国AI闪耀于世界赛场的第一线,背后或多或少都藏着这样的故事。





