日均处理亿万数据!架构师揭秘Flink在滴滴的应用与实践
文章来源:未知
作者:老客SEO
人气:20
 2019-11-07 10:20:13
2019-11-07 10:20:13
滴滴在周末的时候出了一个大事故,地图导航系统全线崩溃,苦了加班的地图研发部门,所以借此机会和大家说说滴滴公司的技术。
在写这篇文章之前,我想跟大家说的是,滴滴确实是一家很不错的公司,和支付宝一样,改变了我们的生活,不是吗?没有呆过滴滴,暂且不谈它内部的氛围是怎么样的,但是做了贡献的企业就应该表扬。
本文主要内容主要包括以下几个:
- 1、Apache Flink 在滴滴的背景
- 2、Apache Flink 在滴滴的平台化
- 3、Apache Flink 在滴滴的生产实践
- 4、Stream SQL
- 5、展望规划
Apache Flink 在滴滴
在滴滴,所有的数据基本上可以分为四个大块:
1、轨迹数据:轨迹数据和订单数据往往是业务方特别关心的。同时因为每一个用户在打车以后,都必须要实时的看到自己的轨迹,所以这些数据有强烈的实时需求
2、交易数据:滴滴的交易数据
3、埋点数据:滴滴各个业务方的埋点数据,包括终端以及后端的所有业务数据
4、日志数据:整个的日志系统都有一些特别强烈的实时需求

在滴滴应用发展的过程中,有一些对延迟性要求特别高的应用场景。比如说滴滴的轨迹数据,以及滴滴网关的日志监控,都对引擎提出了非常大的挑战,要求在一个秒级或者说在一个很短的时间内能够给业务方一个反馈。
在调研以及对比各个流计算引擎以后,由于 Apache Flink(以下简称 Flink)是一个纯流式的处理引擎。发现 Flink 比较满足业务场景。
在滴滴的内部,一个业务形态是事业部特别多,然后有很多业务需要进行实时处理,很多业务部门选择自己搭建 storm 或者 Spark Streaming 小机群。但是一个个小机群会带来一定的问题,例如:由于业务方不会有人专门去做维护流式计算引擎这些相关工作,所以每一次业务方出问题以后,实时计算团队做的最多事情就是进行重启集群,减少这样的一些成本也是对我们一个很大的挑战。
实时计算团队需要能够掌握住流计算引擎,也就是说我们必须要有一个统一的入口,来供大家更方便或者是更快捷更稳定的让业务方使用流计算服务。所以综上考虑,我们最终选择了 Flink 来作为流计算引擎的一个统一入口。
平台化的优点
平台化能给带来什么样的好处呢?很明显就是业务方不再需要自己去维护自己的小机群,也不需要过多的去关心流计算引擎相关的一些问题,业务方只需要专注于业务即可,这显然能够降低业务方的成本。
然后各个业务方如果自己去维护一个小集群的话,就相当于是说每个业务方这里有十台机器,另外一个业务可能也有个七八台机器,然后每个集群上的机器可能就跑了很少的几个应用,业务方的机器的利用率根本上不去,这对公司内部和机器资源来说都是浪费。
第三个就是如果每个业务方自己维护一个小集群的话,无法也没人给业务方任何的稳定性保障,如果将流计算进行平台化以后,平台会给每个业务方承诺一个稳定性保障,并且会有一个稳定性的一个保障体系。
总之流计算平台化的优点可以归结为以下三点:
1、降低流计算使用门槛
2、统一流计算平台,降低机器运维成本,提升机器利用率
3、稳定性保障

通过看上面这一张图,很明显滴滴平台化可以分为以下几个部分:
1、第一个是上游的数据源,在滴滴内部,数据源用的比较多的差不多有两类,第一类是 Kafka(后面会详细讲这个),Kafka 作为滴滴的一个大型的日志系统,因此 Kafka 用的会比较多,然后还有 DDMQ(滴滴内部自研的一个消息队列),这两类中件间在数据流输入方面用的比较多。
2、然后对于中间这一块,是滴滴流计算平台的核心部分,应用管控、StreamSQL、WebIDE、诊断系统都是围绕着这个核心来做的。在滴滴内部现在主要维护了两个引擎,一个是 Flink,还有一个是 Spark Streaming,滴滴流计算平台上的这两个引擎,用户都是能够非常方便的使用到的。
3、再往下,用户提交上来的流计算应用都是由平台去做应用管理的,无论是 Flink 还是 Spark Streaming 应用都是以 On Yarn 模式运行的,流计算平台使用 Yarn 来管理计算资源和集群。对于需要持久化的一些依赖,在底层平台是存储在 HDFS 上的。
4、最后是流计算平台的下游,在下游当然也包括上游的一些中间件,比如 Kafka 和 DDMQ,当然在流计算的过程中,不可避免地要使用到 HBase 或者 MySQL,KV 数据库等下游存储。综上所述这就是滴滴的一个整体平台化的架构。
引擎改进
对于引擎我们主要做了一下这些优化:
1、平台化我们第一个做的工作就是将整个任务提交以及任务管控的各个方面都进行服务化了,既然要流计算平台化,服务化是肯定要做的。
2、第二是在流计算平台化的过程中,为了能够更好的去限制每一个应用,更好的管理应用的资源,流计算平台限制了每个 Yarn-session 上只能提交一个 Job,如果在一个 Yarn-session 上提交多个 Job,平台会进行提示或报错,保证 Job 提交不上去。
3、然后是应用在使用的过程中无法避免的会去做一些升级的操作,比如说一个 Flink Application 在今天使用的时候,很可能没有预估到明天流量会涨很多,这就导致应用在启动的过程中申请到的资源不够,用户可能要重启去修改代码,修改算子的并行度等。但是重启总是会带来一定的业务延迟,因此流计算平台提供了支持动态扩容的新特性。
Flink Application 在重启的时候,以前已经在使用的资源不会被释放,而是会被重新利用,平台会根据新的资源使用情况来进行动态的缩扩。
4、最后一个是在使用官方 Flink 版本的过程中,碰到比较多的问题,例如在 Zookeeper 这一层面就碰到了不少的问题,平台内部修复了很多围绕 Zookeeper 相关的一些问题。例如 Zookeeper 抖动会导致获取不到 CheckPoint 的 ID,在官方的版本里面会存留一些 bug,平台内部已经进行修复了。
流计算任务开发
流计算平台化很大的一个目标,就是让用户开发更简单,能够更加便捷的去使用平台,因此流计算平台提供了多元化的开发方式。在早期主要有两种,第一种是用户在 WebIDE 上进行开发,第二种就是用户在本地的 IDE 中进行开发。现在流计算平台提供了第三种方式:StreamSQL IDE,流计算平台希望通过 StreamSQL 大大的降低用户开发使用流计算的门槛。

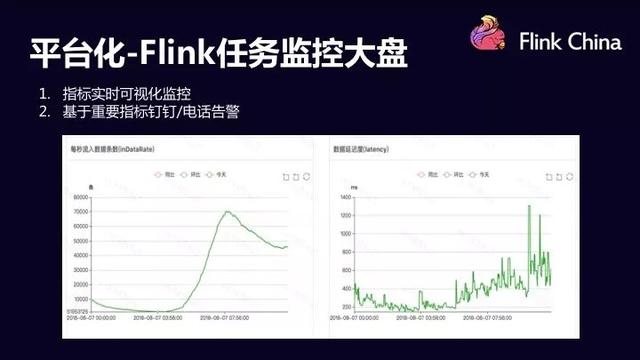
对于流计算平台,用户非常关心任务每时每刻的运行情况,并且用户需要非常实时的进行查看和确认,既然是流式任务,自然对实时要求比较高,因此用户特别关心应用的延迟有多少。
所以流计算平台提供了一个完善的监控大盘,让用户来可以实时的看到他们所关心的每一个指标,当然用户还可以去自定义更个性化的指标。
在图中,分别给出了延迟,和吞吐量(就是应用最大能够消费多大的一个数据量,极限是多少)的实时数据。同时对用户来说,不可能实时的去盯着监控大盘,查看这个任务到底有没有出问题,因此流计算平台也提供了针对各个指标的报警服务,平台会根据适当的策略进行实时告警。
任务诊断体系
虽然流计算平台提供了监控报警的服务,但是用户看到报警数据以后,有可能没法及时有效的去判断自己的实时计算作业到底发生了什么,出现了什么问题。因此流计算平台还提供了任务诊断的服务,流计算平台会把用户任务的一些日志,包括流计算引擎里面的日志进行实时的采集,然后实时的接入到ES里面,这样用户就可以实时的查到指定应用的日志了。
然后对于监控大盘里面看到的监控数据,流计算平台还会在 Druid 中保存一段时间。然后流计算平台修复了 Watermark 没法正常显示等 Flink UI 上面的问题。这样可以让用户能够更好地去查看监控,以及对问题进行诊断。
Flink在滴滴的生产实践
1、生产实践
滴滴的流计算业务在滴滴内部来讲,对于用户认可的业务场景来说,简单的归纳一下,主要是以下四种:
· 实时 ETL
· 实时数据报表
· 实时业务监控。
· 然后还有一个就是 CEP 在线业务。
2、业务场景——实时网管监控
背景
相信很多公司都会有一个业务网关,从网关上面可以看到的各个业务线,网关上面会对每一个业务线去做一些像业务分发这样的逻辑,如果业务线非常庞大,例如滴滴就有很多业务线。
如果某一个业务在某一时刻出现了故障,我们怎么能够快速的发现,同时怎么快速的定位到问题。例如网关后面的每一个业务都会有相关的调用关系,一个 Service A 有可能会依赖于 Service B 或者是 Service C,然后如果一个服务出现故障以后,依赖这个服务的其他服务也有可能会出问题。
但是从应用最上层来看,某个业务曲线出现了下跌,或者是说曲线毛刺很高,这是不符合预期,是异常的。对于这样的一些问题,对内部系统来说,如果一个个模块去排查,是很难排查的,相当于说需要将链路上面的每一个调用关系都一个一个的进行排查,这个过程是相当复杂的。
因此滴滴内部做了一套实时的日志监控系统,能够实时的按业务线进行监控。每一个业务都会细化到每一个子业务,实时的去反映一个系统的服务到底是好还是坏。为了能够支持这样的一些业务场景,我们进行了适当的抽象,把所有的网络日志全部采集到 Kafka 的一个 topic 里面,Topic 里面的日志能够覆盖到滴滴90%的业务,然后我们会按照业务和服务去做一些 Filter,Group By 以及一定范围内的 Window 聚合等计算服务。
架构
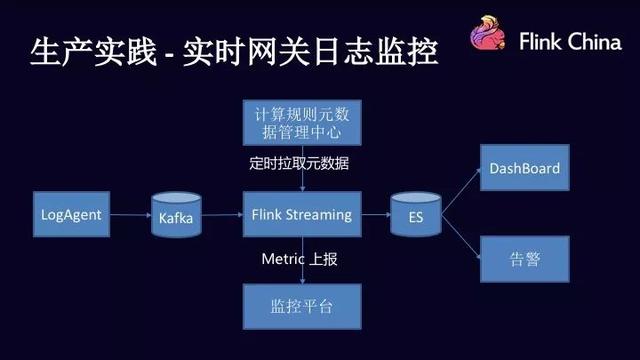
在前面是介绍了我们这个系统的背景,然后现在来看看滴滴这个系统的架构设计。最前面是滴滴的数据采集服务,然后日志数据会被统一收集到 Kafka 中,在中间这一块,主要由 Flink Streaming 来进行处理,这里面是一个 Pipline,例如在这个 Pipline 里面会进行一系列操作:数据展开,数据展开以后,会根据具体的规则进行实时匹配,同时因为规则会动态更新,所以匹配的过程中是需要考虑的。
对于规则的动态更新,在滴滴是通过配置流来实现的。配置流更新以后,会广播到下游的算子中去,下游的算子接收到规则更新以后,会对主数据流进行相应的变更。数据处理完以后,会把数据落到后端的一些系统里面去。比如 ES,数据进入 ES 以后,会有各种各样的使用方式,比如说实时的进行展示,基于这些数据进行判断是否需要进行告警。从整个链路上面来讲,整个实时网关日志架构还是非常清晰的。
3、StreamSQL
滴滴内部的 StreamSQL 正在开发中,以后会作为滴滴内部流计算主要的使用方式,滴滴内部的 StreamSQL 的核心功能如下:
- 第一个就是支持 DDL。滴滴内部使用的数据比较多,格式也比较多,所以滴滴 StreamSQL 的 DDL 具有支持多格式以及多数据源的特点。
- 第二个就是支持 DML,对于 DML 在滴滴,只有一种即:INSERT INTO TABLE,就是插入流数据到某一张表,这个表的一定是一张 Sink 表,并且只能插入到要输出的一个下游。
- 然后是一些常用的、核心的一些功能点。比如 Group Agg、Window Agg,Join。Join 的场景主要有两种:一种是双流上面no-window join以及流和维度表的 Join,同时也支持 UDF、UDTF、UDAF 等用户自定义函数。
在这里简单的介绍一下滴滴定义数据源的一种方式,比如说现在要从 Kafka 中加载数据,我们的元数据具有各种各样的格式,比如说是 JSON 的,需要用户去指定所定义的数据流的 Schema,同时定义 Schema 的时候,必须要指定数据类型。
滴滴用的比较多的一个业务场景是分流 SQL,也就是说一条数据可能会往多个地方写,例如既要写 Hbase 又要写 Kafka 这样的一些需求。Flink 官方的 Stream SQL 是不支持这么去做的,原因可能是因为 SQL 的一些限制导致的,但是滴滴的 Stream SQL 支持分流这一新特性。
同时 Stream Join 也是正在着力推进的一个功能点,双流 noWindow 的 join,在滴滴也是准备支持的,也是滴滴正在不断研发的一个新特性。当然 noWindow 是滴滴给出的一个复杂概念,真正的数据当然还是有一定的状态,Window 里面的数据还是会有一定的过期时间的,只是说滴滴正在尝试天级别的一个过期时间。在用户设置以后,会在指定的一个时间,比如说每天凌晨或者说固定的一个时间点,将一些过去的数据一次性的清空掉。最后对于维度表,滴滴 Stream SQL Join 的永远是当前表,并且只支持当前表,不支持和历史表进行 Join,也不支持数据的回撤。

- 我们希望 StreamSQL 以后会承载滴滴内部至少90%的流计算任务,越来越多的任务都会慢慢的往 StreamSQL 上面迁移,比如说增加的新任务,以及历史遗留的一些任务。
- 第二个是关于 CEP,滴滴也会将其融入到 StreamSQL 的体系中,同时会不断的进行这方面性能优化。
- 第三点是关于业务场景的,在滴滴,监控和实时报表这样的一些业务场景会占比较多的一个部分。以后滴滴会探索开发更多业务场景,让 Flink 不断成长。
- 第四点是为了去应对流量突发带来的稳定性的一些问题,滴滴会在动态扩容上做更多的一些事情,同时滴滴也正在尝试在算子级别进行资源的自动缩扩。





