专访考拉阅读CEO赵梓淳:用AI打造中国的“蓝思标准”
文章来源:老客SEO
作者:老客SEO
人气:14
 2019-05-21 18:06:13
2019-05-21 18:06:13
近日,专注中文分级阅读系统的考拉阅读宣布完成了2000万美金B轮融资,距去年12月A轮融资过去了9个月时间。
谈到A轮以后的最新进展,赵梓淳表示,考拉阅读App总日活量已经增涨到近百万,平均日停留时长30分钟,次日和次周的留存率达到70%以上,产品半年时间发版26次。
雷锋网来到考拉阅读北京办公室,专访了考拉阅读CEO赵梓淳。

中文分级阅读难点在哪?
分级阅读有几百年的历史,欧美都比较普及。在中国,引入分级阅读的时间也不短,但是,中国跟美国最大的不同在于,无论是像中文在线还是其他公司,基本上停留在书单形式,根据学生年级或年龄来区分书单。
“但是,真正的分级阅读应该像欧美那样,根据学生的阅读能力进行匹配。通过分级阅读把阅读解放出来,让孩子找到适合自己的东西。但为什么之前没人像我们这样做,最大的难点就在于中文文本难度的测量,即如何科学划分文本难度的等级。”
首先,中文和英文存在着非常大的差异,不同于西方印欧语系繁复的格标记语法系统,汉语语法过于灵活、意合语义相当复杂。英文的基础组成单位是26个字母,中文的组成单位是字,常用的汉字大概就有3500个。《康熙字典》收录的汉字大概就有8万到10万个汉字,这种复杂构成的稀缺性会导致分析中文的时候,往往需要更庞大的语料。
第二,现代汉语的历史很短,中国的学者、专家,对中国的汉语言、语言学的一些累积和沉淀其实很少,真正进行科学化的一些研究时间并不长,积淀也不够。
第三,分级阅读还涉及到数据挖掘、语言学、测量心理学、阅读测量学等各学科的联动。
最后,更关键的是,在深度学习普遍应用之前,没有技术能解决这样的问题。10年前或者20年前的技术,其实不太能解决当时遇到的这个问题,例如美国的蓝思分级,主要运用的是语言学家传统的统计学,所以其实没有用太多的高深的技术。中文阅读分级要想完成规模化的解决方案只能依赖于现代科学技术的发展。
据介绍,考拉阅读历时两年,构建起全球最大的中文分级底层语料库,结合语言学、测量心理学以及深度神经网络为代表的前沿AI算法解决了这一难题。
“我们邀请常年参加教学研究的专业学者和经验丰富的教学专家参与难度判断和标准制定,通过上万篇文本测试,发现准确度能达到93%左右。”
AI驱动的学习系统
图片来源:考拉阅读App界面
考拉阅读的产品有学生端、教师端App,还有考拉家长微信小程序。有两项特点。
一是游戏化。“我们最早做考拉阅读产品时,借鉴了国外的产品,做的比较严肃,缺乏游戏和动漫色彩。但做了一段时间后发现,严肃产品对中国学生缺乏吸引力,小学生还是喜欢比较游戏化的东西,后来对此做了调整,引进了一位优酷少儿的设计师,使整个UI和孩子的契合度越来越高。”
雷锋网试用了考拉阅读学生端App,主界面第一栏即为“短文星球”小游戏;第二栏的「探索世界」为ER值不同的阅读文本;第三栏「听书电台」为和喜马拉雅合作的音频栏目;第三栏为组词闯关游戏,第四栏又转为标注ER值的故事文本,此外,还有童话岛、每日晨读、书籍专题、同学热读、书籍海洋等阅读栏目。
二是AI驱动。“我们是将底层的AI算法应用到产品层面。这套算法类似于今日头条,只不过今日头条是内容推动算法,无论是交叉推荐还是做用户画像,都是根据兴趣推荐用户喜欢的内容。而我们的推荐算法是根据学生阅读能力进行匹配,使用的频率越多,推荐的准确度就越高。”

图片来源:考拉阅读提供
“因为中文句子相较英文要复杂得多,机器在理解中文第一步时就会遇到词性分析、语言模型上的困难。所以,有赖于现在流行的AI技术,如RNN、LSTM等深度学习技术,可以弥补中文在NLP上的缺失。我们将一个句子按照句法树、依赖关联等予以拆解,以分析每一个成分在句子中的比重,从而实现阅读文本的难度分级。”
据介绍,考拉阅读一共处理了1300万字的非平衡语料库和2亿字的平衡语料库。其中,非平衡语料库主要来自各个版本的小学教材及其教辅资料;平衡语料库指一个孩子在日常生活中需要真实接触的语料,如,按照一位10岁小孩需要看20%的名著小说、50%的课文和20%的漫画这种比例来配语料库。
考拉阅读的人工智能主要应用,除了打造底层分级标准,还有自适应学习系统,即学生端App会根据学生阅读能力自动推荐相应内容。
谈到现在火热的自适应学习,赵梓淳表示,自适应学习不宜被过分夸大,基于知识图谱的自适应学习有一定意义,可以避免学生重复做已经掌握的题目,节省时间提高效率,“但这件事并没有多难,其实就是把知识图谱做的足够细,而这个主要考验的是教研能力,那你说这个事儿有多颠覆呢?坦白说,没有多颠覆。”
此外,考拉阅读也正在进行智能语音产品研发,可以通过语音输入测试学生的普通话标准程度。
打造中国的“蓝思标准”
国外的分级阅读标准体系已经很成熟,比如培生公司推出的测定少儿英文阅读能力的DRA(Developmental Reading Assessment)发展性阅读评估体系;英国 Renaissance Learning 公司开发的AR(Accelerated Reader)分级系统;还有著名的蓝思阅读测评体系(The Lexile Framework for Reading),该体系由美国Metametircs教育公司经过15年研究开发出来,美国使用蓝思的机构遍布50个州,约覆盖全国学生人数的50%。
蓝思阅读测评体系从读物难度和读者阅读能力两方面进行衡量,使用的是同一个度量标尺,因此读者可以根据自己的阅读能力,选择适合自己的读物。难度范围为0L~1700L,数字越小表示读物难度越低或读者阅读能力越低,反之则表示读物难度越高或读者阅读能力越高。主要从两个维度来衡量读物难度,即语义难度(Semantic Difficulty)和句法难度(Syntactic Complexity)。
考拉阅读推出的中文分级阅读标准(ER Framework )借鉴了国外的“词、句”的分析思想,度量方式也和蓝思极为相似。(ER为考拉阅读品牌所属公司享阅科技的英文名Enjoy Reading的缩写。)
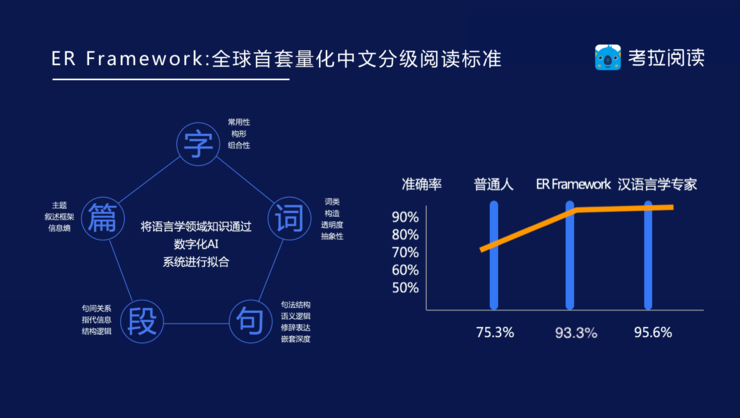
图片来源:考拉阅读提供
一方面,把任意的中文文本测出来,从200ER到1300ER,以10为一个进制。另一方面,运用测量心理学、阅读测量学和语言学的方法,测人的阅读能力,也是从200ER到1300ER,以10为一个进制。
“如果一个孩子测出来是600ER的阅读能力,他到底能够看多大难度的文本?是600还是610?我们提出一个叫CPD的概念,借鉴了著名心理学家维果斯基提出的‘最近发展区’,即能力范围内可以做得到的区间。 别总做一些很简单的事情,但如果做特别难的事情,久而久之也丧失信心。”
“例如600ER的孩子,我们做了大量的实验,她/他的CPD范围大概是550到700。这个区间代表了孩子探究文本的理解程度在50%到59%之间,既不会因为文本太难而读不懂,也不会因为文本太简单而读不到新内容。”

图片来源:考拉阅读App截图
具体测试方式,赵梓淳向雷锋网解释,是在手机上进行时长约三分钟的测试,即可估测学生的阅读等级。
至于商业模式,“目前主要是和公立学校合作,已经在二、三线城市的近万所小学落地。未来一定是ToC的,但现在没有做任何尝试,学生、老师和家长都可以免费使用。我们目前其实还不太考虑盈利的事,先扩大规模,如果说全中国小学生最后能够用ER值来表征自己的阅读能力,所有的人都用ER值来表征文本难度,这件事情背后蕴藏着很大的机会。”
“我们准备明年公布整个底层标准,所采用的算法也可能会相继公布。”
当雷锋网问到考拉阅读目前面临的最大挑战是什么,赵梓淳表示:“最大的挑战是没有竞争对手可以对标。这条路以前没有人走过,不知道参照谁,每一步都要靠自己摸索。”





