银行数据仓库的系统架构是什么?看这篇足矣
文章来源:未知
作者:老客SEO
人气:19
 2019-11-07 10:47:35
2019-11-07 10:47:35
UML对系统架构的定义是:系统的组织结构,包括系统分解的组成部分,它们的关联性,交互,机制和指导原则,例如对系统群就是定义各子系统的功能和职责,如贷款系统群可能分为进件申请、核额、交易账务、贷后管理、管理台等子系统,对于系统就是定义各模块的功能和层次,例如管理台包括权限管理、用户管理、交易管理、逾期管理、统计分析等功能。
技术架构是指从技术实现层面描述系统,主要是根据系统架构组成部分确定每层使用什么技术框架,例如中间件、WebService等。
那对于数据仓库系统群具体可以分为哪些部分以及他们的具体实现技术如何呢?以下是银行数据仓库的系统功能图:
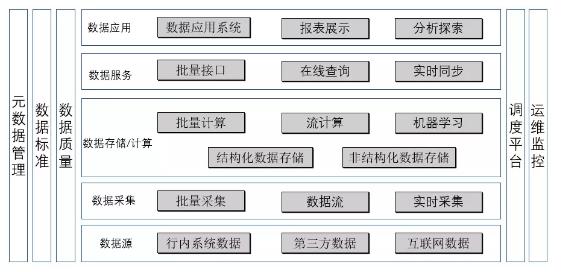
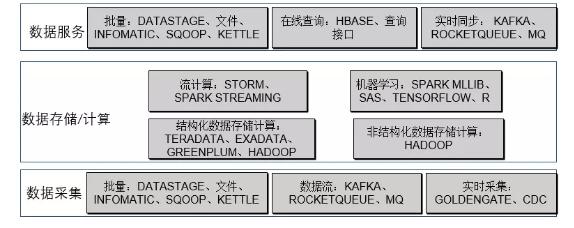
1、数据源:
主要是指行内交易系统、外部采购或合作的第三方数据等3类、包括结构化数据以及非结构化的数据,结构化数据主要是存储在各个行内系统数据库中的表数据,非结构化数据包括图片、语音、文档等类型的数据。
2、数据采集:
即如何将数据从数据源获取到数据仓库中,就是我们常说的ETL随着数据仓库功能的发展这部分不仅仅包括批量数据获取还包括实时数据流以及数据库数据实时采集:
(1)批量采集:主要包括从数据源获取大批量的数据,这是银行数据仓库主要的数据采集方式,批量采集的采集数据频率较低,一般是每日凌晨获取上一天的数据,有些场景也可以每小时采集一次,由于采集的数据量一般较大,对数据源也有IO的影响,因此不建议采集频率太高。
在技术实现中,批量采集工具需要能支持多种数据源的采集和加载,批量采集可选择的工具较多,可以采用商业化软件如IBM的DATASTAGE以及INFORMATICA公司的INFORMATICA,也可以采用开源的SQOOP和KETTLE。也可以采用各关系型数据库以及HADOOP自带的文件导出和导入功能。
(2)实时采集:指实时同步源系统的数据库数据到数据仓库,这样可以在数据仓库中实时分析数据。实时采集通过专门的工具监控源系统数据库日志进行数据同步,数据源系统无需改造,这种采集方式针对数据统计时效性非常高的场景。
在技术实现中,实时采集工具需要支持从多种类型数据源到多种类型目标数据库的实时同步,这块商业化软件比较成熟,如ORACLE的GOLDENGATE、IBM的InfoSphere Change Data Capture等软件。开源软件中kettle也支持数据库实时同步,但需要在源表增加时间戳字段。
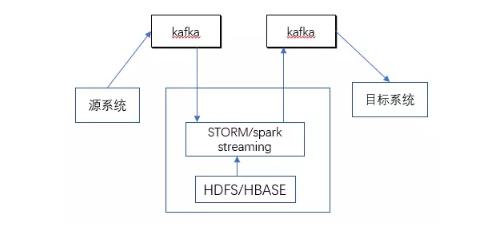
(3)数据流采集:即通过Queue的方式从数据源系统获得数据流消息,数据仓库实时获取Queue中的消息进行实时数据流计算。这种数据采集方式也是面向统计时效非常高的场景,需要数据源系统增加实时发送消息的功能。
在技术实现中,由于数据流计算在互联网公司使用广泛,涌现出许多优秀的开源软件,如开源的KAFKA、ROCKETQUEUE等QUEUE工具,可以支持实时监控文件、数据库的变化并将变化数据发送到QUEUE中的开源软件FLUME。对于MYSQL也可以通过BINLOG和SHYIKO监控MYSQL日志,将数据变化发送到QUEUE中,那在商业化软件中IBM的MQ是各银行经常使用的中间件。
3、数据存储/计算:
数据存储计算是数据仓库的主要功能。数据存储主要指结构化数据和非结构化数据的按格式存储,计算指基于存储的数据进行关联、汇总、数值计算等批量处理、实时流计算和复杂的机器学习。
实时流计算主要指对大规模流动数据在不断变化的过程中实时地进行分析,比如实时展示目前银行所有转账的笔数和汇总金额。需要将每笔转账进行不断计算。目前在银行中应用场景还较少,但随着互联网渠道的发展后续也将出现更多的应用场景。
由于数据仓库是银行的数据枢纽,银行的所有业务数据都会在数据仓库保留,因此数据量较大,一般小银行数据量在TB级,股份制银行大概在PB级,国有大银行在ZB级。因此存储和计算的的可扩展性、性能都很重要。那在目前银行中数据仓库的存储和计算一般采用MPP数据库(大规模并行数据库)和HADOOP相结合的技术方案。
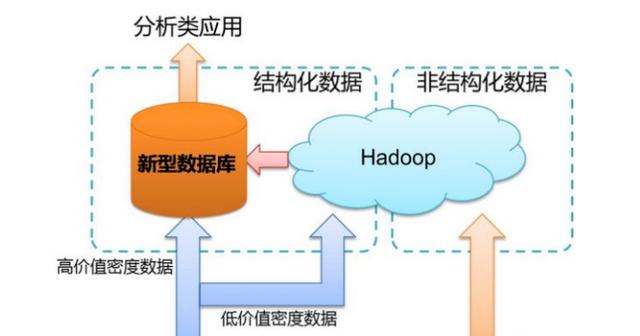
(1)MPP数据库:主要是面向结构化数据存储、批量计算和机器学习。在HADOOP出现前,商用的MPP数据库是数据仓库的主流技术平台,它使用简单,同时具有超大规模计算能力和良好的计算性能、扩展性。如TERADATA公司的TERADATA数据库、ORACLE公司的ORACLE一体机、IBM的NETEZZA一体机。其中TERADATA公司的TERADATA数据库在早期是一枝独秀,我国国有大银行的数据仓库最早建立时大部分都采用了TERADATA数据库。近年来ORACLE的EXADATA市场占有率也逐步提升,开源的MPP数据库最有名的是由商业转为开源GREENPLUM,目前腾讯云的TIBASE、阿里云的HybridDB for PostgreSQL都是基于GREENPLUM优化的。
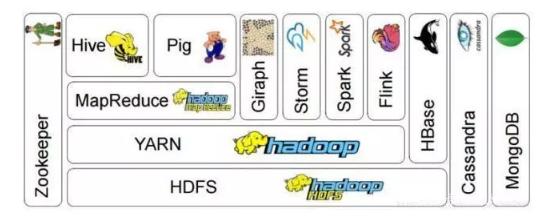
(2)HADOOP平台:HADOOP平台支持结构化数据和非结构化数据的存储和计算。由于MPP数据库价格高,且扩展性也有一定局限。很难满足互联网公司超大数据量及非结构化数据的计算需求,因此HADOOP软件生态体系应运而生并发展越来越成熟,成为互联网公司大数据处理的标配平台。2015年左右,随着HADOOP平台的完善及商用(商用版本如华为、星环科技;开源版本如CLOUDERA、Hortonworks),银行也逐步使用HADOOP平台和MPP数据一起作为数据仓库的存储和计算平台。其中批量计算一般使用HIVE和SPARK,流计算一般使用STORM和SPARKSTREAMING,机器学习可以采用HADOOP生态的SPARKMLLIB、MAHOUT,也可以使用TENSORFLOW、SAS、R等支持HADOOP平台专门的机器学习工具,目前许多公司在研发推出的人工智能平台(机器学习建模平台)也都把HADOOP平台作为数据存储和计算平台,如第四范式、星环科技等。
4、数据服务:
数据服务主要指如何为银行其它系统提供数据服务,随着数据仓库体系的发展,数据仓库不仅仅能按批量的方式提供数据计算结果,还可以实时提供数据服务。
(1)批量接口:按约定的接口方式将数据批量提供给数据应用系统,一般每天1次,可以按文件的方式放到约定的服务器,也可以通过数据采集部分提到的ETL工具直接将数据同步到应用系统的数据库中。
(2)在线查询:提供实时查询的接口,并发布到银行交易总线,由其他业务系统或数据系统实时调用,比如银行的每年的账单总结(类似支付宝每年账单)一般由数据仓库根据每个客户1年的交易流水,统计出转账、消费、收入等数据并提供给渠道系统如手机银行、网上银行进行展示。那在技术实现方面,接口服务开发一般按各行的开发规范来实现,如web service或http+xml,大部分银行使用JAVA进行开发,如果接口TPS不高,一般的MPP数据库也足够支持,无需进行数据移动,如果TPS比较高,可以将数据加工结果放到HADOOP HBASE进行数据存储和查询。
(3)实时同步:实时同步主要是实时数据流计算后将结果实时同步给数据使用系统,同时将结果发布到QUEUE中,由目标系统进行订阅,实时获取。
5、数据应用:
数据应用主要是将数据通过数据服务提供给各应用系统,由各系统进行数据分析和成果展示。那主要有以下几类:
(1)数据应用系统:主要指使用数据的系统,在银行包括客户关系管理、管理会计、绩效管理、新资本协议系统群等数据系统,也包括核心、贷款等交易系统。
(2)报表平台:报表平台能将数据快速展示成图表、能通过建立数据立方体(CUBE)提供数据钻取(向上或向下变换数据分析维度)功能,方便业务人员快速查询和分析数据。那报表工具目前商用的比较成熟,展示也更美观,常见的有Finereport、TABLEAU等,开源的报表工具功能较弱,常用的有birt、ireport、jasperreport、KYLIN(基于hadoop建立CUBE)等。
(3)分析探索:有的银行也叫数据实验室或分析集市,主要指提供给业务人员自行分析的平台,银行业务部门的分析人员经常使用SQL自行分析数据,也会使用SAS或R、PYTHON进行数据挖掘,随着AI技术的深入,也逐步在尝试TENSORFLOW等深度学习的工具来分析银行数据。由于数据分析工作时间不固定,且消耗计算资源较大,因此一般都是单独给业务人员搭建一套或多套的分析环境,每套环境包括HADOOP或数据库作为数据存储,SAS、R、TENSORFLOW等作为分析引擎。同时还需要定期(一般T+1)更新分析环境的数据,提高数据分析的及时性。
相关文章
-
出去千万别说UI和美工是一个职业,千万别暴露你的缺点哦
文章来源:老铁商城2019-10-31 -
我优化多年的 C 语言竟然被 80行Haskell 打败了?
文章来源:老铁商城2019-10-20 -
当程序员遇到中秋节,会产生怎样的化学反应......
文章来源:老铁商城2019-09-18 -
淘宝、京东这些网站的哪个部分用了web前端技术?你能学会吗?
文章来源:老铁商城2019-09-18 -
Linux和哪些行业有关?2019Linux运维必备哪些技能?
文章来源:老铁商城2019-09-18 -
公认最具影响力的4种编程语言!平均薪资20K,Java第一
文章来源:老铁商城2019-09-18 -
PYPL 9 月编程排行榜:Python第一,继续称霸!就业薪资怎么样?
文章来源:老铁商城2019-09-18





