深度分析|一文读懂银行数据架构体系
文章来源:未知
作者:老客SEO
人气:15
 2019-11-07 10:46:54
2019-11-07 10:46:54
上一篇讲了银行数据仓库的系统架构,这次给大家讲讲数据架构。如果一个系统,没有数据架构,那肯定是在吹牛。
狭义的数据仓库数据架构用来特指数据分布,广义的数据仓库数据架构还包括数据模型、数据标准和数据治理。即包含相对静态部分如元数据、业务对象数据模型、主数据、共享数据,也包含相对动态部分如数据流转、ETL、整合、访问应用和数据全生命周期管控治理。
数据架构层面通过数据分类、分层部署等手段,从非功能性视角将数据合理布局。通过整体架构管控和设计,支持业务操作类和管理分析类应用(系统),满足业务发展及IT转型对数据的需求,架构的扩展性和适应性能够提升数据分析应用的及时性、灵活性和准确性。
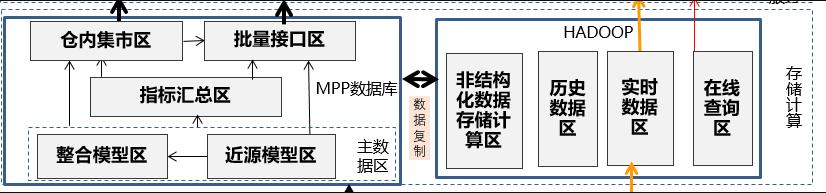
那实际情况下各个银行的数据架构体系会有所不同,根据各行的业务发展、客户数据量、交易数据量、功能需求等会有不同的演变路径以及发展方向。一般国有银行、股份制银行等全国性的银行业务较复杂,数据量也较多,数据架构也因此进化较快。常见的数据架构分区如下图所示:
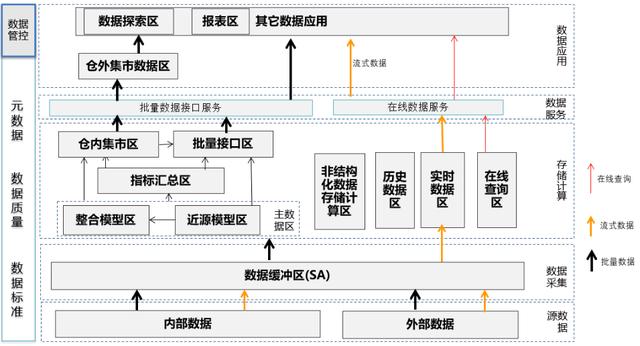
1、数据采集层
数据缓冲区的数据主要是将数据从源系统加载到数据仓库中,作为数据在数据仓库的起点,数据缓存区数据只保留7-10天,以备数据问题处理,数据缓冲区的数据除了标准化的处理,最好直接获取源系统未经加工的数据,以便一次抽取,多次使用。
标准化处理主要有编码统一转化、异常字符清理等,以便后续处理。数据采集层不仅仅只应用于数据仓库相关,也可以适用于各交易系统的批量数据或文件传输和交换,所以在全行系统层面制定规范。
2、存储计算层
(1)主数据区:
指结构化数据的主数据区,这部分数据包括了所有的基础明细数据以及历史数据,其它区域的结构化数据都是由主数据区数据加工而来。那主数据区主要有两种模型:近源模型层和整合模型层。一般在实践过程中可以两个区域都有,也可以只有任意一个区域。这两个区的数据都通过历史拉链或历史流水的方式保留历史数据,如果有数据标准,这两个区的数据按数据标准进行字段属性如代码值、长度、精度的标准化,那这两个区的数据主要在模型设计方面有所不同:
①近源模型区:表结构设计和源系统类似,在源系统表基础上增加标准化字段以及历史数据保存算法的数据日期字段,近源模型层的特点是保留源系统表所有信息,在建模和运行效率上比较高,但数据整合性不高,一些交易系统设计的表结构并不直接适用数据分析和加工。
②整合模型区:整合模型区按主题进行数据整合、表设计以三范式为主,模型稳定,数据冗余少,那这里模型稳定是指即使源系统表结构如何变化,只要实体之间关系和属性不变,那整合模型也可以保持基本不变。模型稳定的一个好处就是可以屏蔽源系统变化,避免下游应用系统重复改造。
举个栗子:个人信贷系统升级,将使用新的系统,那所有表结构都会发生变化,如果直接使用近源模型区数据,那对于后续加工变化很大,同时时间跨度较大的分析(如年报)需要分别考虑新旧个人信贷系统的数据加工规则,如果使用整合模型,那整合模型变动不会太大,对于历史数据也能同时存在于一个模型(一套表)中,对于后续应用加工影响较小。同时整合模型会在客户、账户、签约等各主要维度进行分析梳理,形成整体视图,有利于从全行视角分析。例如客户整合可以区分客户唯一性,获得客户视图;产品和签约的整合可以清楚看到客户在行内的购买的所有产品和签约。方便后续客户分析。
(2)指标汇总区:
由于主数据区的数据并不合适直接提供给数据系统分析使用,因此指标汇总区是整合各数据应用的加工需求,按事实表(宽表)和维度表进行模型设计,对主数据区数据进行关联、公共指标加工,提供给多个数据应用使用,那指标汇总区可按协议(账户)、产品、客户、科目、机构等逐层汇总,指标汇总区可以消除各系统对于同一个指标分别加工导致的口径差异。
(3)集市区(仓内):
仓内集市主要指和数据仓库在同一个物理平台中的集市,可以直接访问主数据区,指标汇总区数据、减少数据批量转移的成本,利用数据仓库平台分析性能快速进行数据加工,那数据集市的划分可按业务部门或下游系统关联度进行集市划分,如财务集市面向管理会计等财务分析应用进行专门的数据加工、使用者主要为计划财务部。监管集市主要面向给人行、银监进行监管报送报表的加工,涉及多个业务管理部门。
(4)批量接口区:
数据仓库给各下游数据应用系统、仓外集市的数据接口加工区,按双方约定的数据格式提供给数据应用系统,批量接口区按接口协议做简单关联,不做复杂加工,如果平台支持视图,接口区可以只有视图提供给下游接口,减少数据冗余。
(5)非结构化数据存储计算区:
主要对非结构化数据进行存储计算,按一定的数据类型、来源、用途进行区域划分,方便实时查看和分析;
(6)历史数据区:
面向主数据区和非结构化数据区的历史数据归档和查询。主数据区和非结构化数据区一般只保留1-3年的数据,之前的数据使用率低,可专门归档到历史数据区,提高主数据区的性能;同时历史数据区可以采用成本较低的设备,降低成本。
(7)实时数据区:
实时数据区主要面向流式数据的加工和处理,同时对于流处理所需的主数据区数据可以直接访问也可以存储一份在实时数据区。
(8)在线访问区:
在线访问区数据是数据加工结果数据,以实时数据接口方式提供给外部使用。改部分数据可以采用HBASE提供在线查询服务。
3、仓外集市数据区
仓外数据集市和仓内数据集市区别只是和数据仓库不在同一物理平台,但一样面向特定的数据应用进行加工分析,一般随着数据量的增加,数据仓库的平台负荷过大往往会将集市从仓内移到仓外,或者对于需24小时随时提供数据处理的数据集市,为了不与数据仓库平台竞争资源,也一般选择在仓外建设数据集市。
4、报表区
报表区数据是加工后的报表结果数据,为报表平台提供展示数据,因为报表系统往往是7*24小时提供服务,因此在数据平台外单独建立报表平台,减少耦合性,在行内可以建设统一的报表平台,对报表的开发、整合、维护、下线进行统一管理,减少重复报表开发。
5、数据探索区
数据探索区是提供给各业务部门进行数据探索的区域,该区域的数据根据业务分析需求从数据仓库进行加载,并T+1进行更新,由业务同事对数据进行自由分析和挖掘。该平台一般性能要求也比较高,可以使用MPP数据库或HADOOP平台进行技术实现。由于业务人员使用比较随意,该区域需要注意历史数据的清理,避免过多冗余无用的数据占用大量空间。
从数据分层来看,存储计算区是最为核心的部分,存储计算区大部分银行是由MPP数据库和HADOOP平台共同来实现,部分互联网银行单独使用HADOOP平台来实现。以下是一种常见的MPP和HADOOP平台协作的存储计算数据区的技术实现:
从各数据区域的使用团队来看,如果全行数据进行统一存储管理或者采用数据中台,那存储计算区建议由统一团队进行开发维护,数据集市区、数据采集区、数据实验区、报表区可以统一规范和技术平台,由各数据应用团队负责各自程序维护,通过用户权限管理进行隔离。
相关文章
-
出去千万别说UI和美工是一个职业,千万别暴露你的缺点哦
文章来源:老铁商城2019-10-31 -
我优化多年的 C 语言竟然被 80行Haskell 打败了?
文章来源:老铁商城2019-10-20 -
当程序员遇到中秋节,会产生怎样的化学反应......
文章来源:老铁商城2019-09-18 -
淘宝、京东这些网站的哪个部分用了web前端技术?你能学会吗?
文章来源:老铁商城2019-09-18 -
Linux和哪些行业有关?2019Linux运维必备哪些技能?
文章来源:老铁商城2019-09-18 -
公认最具影响力的4种编程语言!平均薪资20K,Java第一
文章来源:老铁商城2019-09-18 -
PYPL 9 月编程排行榜:Python第一,继续称霸!就业薪资怎么样?
文章来源:老铁商城2019-09-18





