深度解析搜索引擎爬虫的工作原理 「站长必看」
文章来源:晴天外链
作者:百度商业推广多少
人气:16
 2020-08-27 20:39:10
2020-08-27 20:39:10
作为一名合格的SEOER,我们接触的是网站,接触的是搜索引擎,既然如此,那么我们就必须对搜索引擎有一定的了解,只有这样才能做出效果。严格来说搜索引擎是通过一种“爬虫(蜘蛛)”这样的计算机程序来抓取我们网页上面的信息的,总体来讲,搜索引擎爬虫的工作原理一共分为抓取、过滤、收录索引、排序四大环节,下面我们一起来看一下。
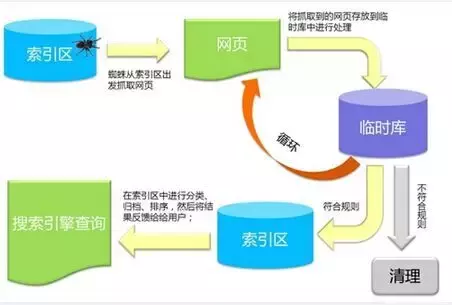
抓取
抓取环节是第一步,搜索引擎收录你网页的第一步,它是指搜索引擎爬虫通过链接访问你的网站,进而进行深度和广度的抓取,深度抓取是指从上至下抓取,广度抓取则是指从左往右抓取,并且这两种抓取方式都是同时进行的。通常爬虫会抓取你网页上的文字、链接、图片等等信息,或者从严格意义上说,爬虫其实抓取的是你当前网页的代码。
过滤
过滤环节是指当前页面信息被爬虫抓取之后,它会将抓取的信息放入搜索引擎的一个临时数据库中,这个临时数据库是用来暂时存放和筛选过滤信息的容器,爬虫将抓取到的信息放入临时数据库中之后,接着它就会继续去别的网站执行任务去了。而暂时存放在临时数据库中的网页信息这个时候将被根据页面的质量接受筛选过滤处理,从而决定该页面是否被收录还是被过滤掉,这就是一个过滤的环节。
收录
收录环节在这里指的是那些存放在搜索引擎临时数据中,通过筛选环节并且顺利通过考核的页面,则会进入到收录环节。但是该页面被收录并不意味着可以被搜索到,它还需要有更具实际意义的索引,这样才能被用户搜索查询到,所以在这里收录并不等于索引(不信去百度官方看文档)。
很多站长都认为网页是需要先被搜索引擎收录之后才被索引,其实这是一种不正确的认识。一个被收录的网页我们可以通过搜索该页面的链接地址查看到结果,但是当我们去搜索当前网页全标题的时候却找不到,其实这就是网页被收录了,但是并没有被索引的情况。正是因为该页面没有进入搜索引擎的索引库当中,所以用户无法检索到。
排序
排序通常都是最后一个环节了,一旦你的网页通过了收录索引这个环节,那么这个时候其实就可以参与排序检索了,但是通常网页排序又会跟众多因素有关,所以我们是无法保证该页面的排序位置的。不过在这其中最直观的影响应该还是网页内容质量和网站的权重,这两者影响非常大,这也是为什么有的老网站发布一篇帖子就能排名在首页,而你发布一篇帖子排名都找不到的原因之一。
以上就是关于搜索引擎爬虫工作原理四大环节的解析,虽然描述的还不是特别详细,还有很多细节方面的东西没有描述出来,但是有的东西想要完全用文字表达出来确实也有一定的难度。不过通过上文来看的话相信大家还是可以获取到很多信息的。
还是那句老话,看过了并不代表领悟了,不实际吸收运用我不过又浪费了你几分钟而已,意义不大!好好珍惜现在的时间,好好享受现在的工作,恐怕之后的日子里你再也无法体会到当下的演出了!





