内部架构师分享!这是你不知道的美团的大数据平台架构
文章来源:未知
作者:老客SEO
人气:13
 2019-11-07 10:18:59
2019-11-07 10:18:59
各位,数据仓库系列已经更新完毕,接下来会和大家聊聊最近很火的大数据,文末会有一个小惊喜给各位。
老样子,讲一个东西就得从它的最底层讲起,也就是我们通常所说的架构,笔者会结合自己多年的从业经验,把整个架构中的每一个细节拿出来深度剖析,希望能够帮助到屏幕前的你们。
随着大数据技术的发展,数据挖掘、大数据分析等专有名词曝光度越来越高,但是在类似于Hadoop系列的大数据分析系统大行其道之前,以BI系统为主的数据分析,已经有了非常成熟和稳定的技术方案和生态系统,对于BI系统来说,大概的架构图如下:
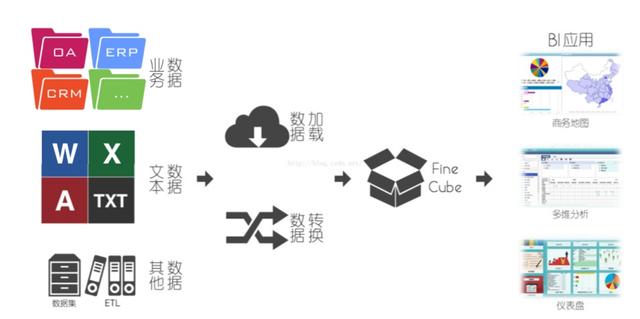
传统大数据架构是这样的:
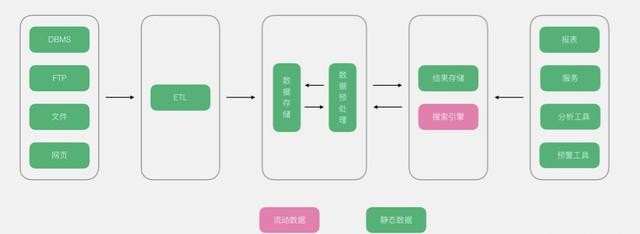
之所以叫传统大数据架构,是因为其定位是为了解决传统BI的问题,简单来说,数据分析的业务没有发生任何变化,但是因为数据量、性能等问题导致系统无法正常使用,需要进行升级改造,那么此类架构便是为了解决这个问题。
那现在的大数据平台的架构是什么样的?
不久前,刷脉脉知道美团的市值快接近700亿了,作为我曾经工作过的公司,我还是为它感到高兴,它是否可以超过百度把BAT变成ATM,这点我不做评价,但我一直想写点什么,所以就以美团的架构为例,和大家讲讲吧。
一、美团大数据平台的架构
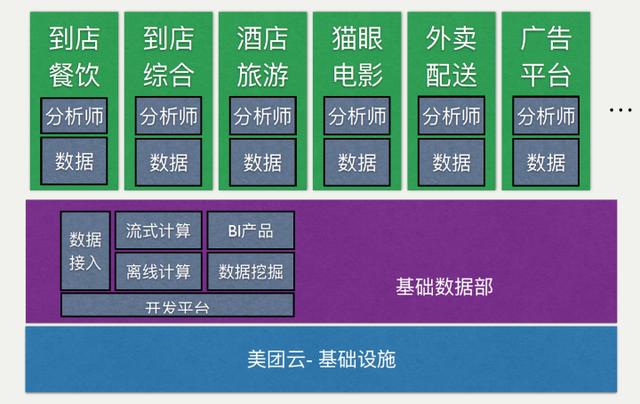
1、总体架构
2、数据流架构
下面我以数据流的架构角度介绍一下整个美团数据平台的架构,最左边首先从业务流到平台,分别到实时计算,离线数据。

最下面支撑这一系列的有一个数据开发的平台,这张图比较细,这是详细的整体数据流架构图。包括最左边是数据接入,上面是流式计算,然后是Hadoop离线计算。
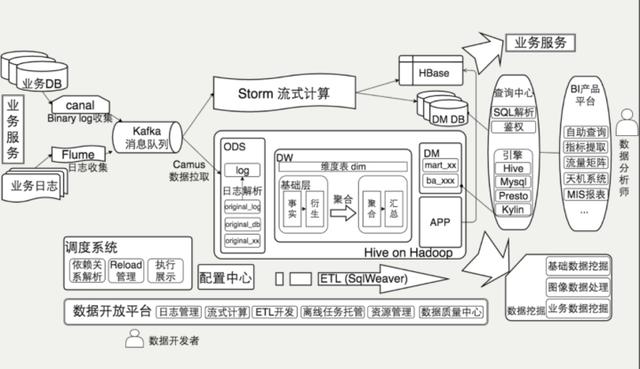
将上图左上角扩大来看,首先是数据接入与流式计算,电商系统产生数据分两个场景,一个是追加型的日志型数据,另外是关系型数据的维度数据。对于前一种是使用Flume比较标准化的大家都在用的日志收集系统,最近使用了阿里开源的Canal,之后有三个下游,所有的流式数据都是走Kafka这套流走的。
数据收集特性:
对于数据收集平台,日志数据是多接口的,可以打到文件里观察文件,也可以更新数据库表。关系型数据库是基于Binlog获取增量的,如果做数据仓库的话有大量的关系型数据库,有一些变更没法发现等情况,可以通过Binlog手段可以解决。通过一个Kafka消息队列集中化分发支持下游,目前支持了850以上的日志类型,峰值每秒有百万介入。
流式计算平台特性:
构建流式计算平台的时候充分考虑了开发的复杂度,基于Storm。有一个在线的开发平台,测试开发过程都在在线平台上做,提供一个相当于对Storm应用场景的封装,有一个拓扑开发框架,因为是流式计算,我们也做了延迟统计和报警,现在支持1100以上的实时拓扑,秒级实时数据流延迟。这上面可以配置公司内部定的某个参数,某个代码,可以在平台上编译有调试。
离线计算是基于Hadoop的数据仓库数据应用,主要是展示了对数据仓库分成的规划,包括原始数据接入,到核心数据仓库的基础层,包括事实和衍生事实,维度表横跨了聚合的结果,最右边提供了数据应用:一些挖掘和使用场景,上面是各个业务线自建的需求报表和分析库。
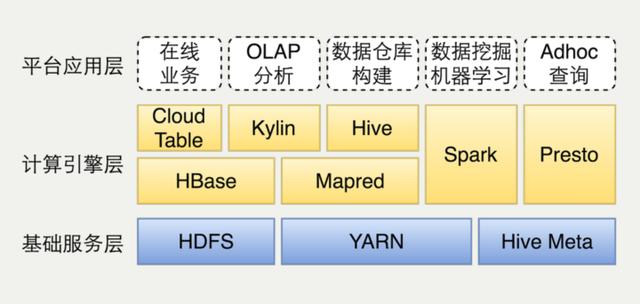
这幅图是离线数据平台的部署架构图,最下面是三个基础服务,包括Yarn、HDFS、HiveMeta。不同的计算场景提供不同的计算引擎支持。如果是新建的公司,其实这里是有一些架构选型的。Cloud Table是自己做的HBase分装封口。我们使用Hive构建数据仓库,用Spark在数据挖掘和机器学习,Presto支持Adhoc上查询,也可能写一些复杂的SQL。对应关系这里Presto没有部署到Yarn,跟Yarn是同步的,Spark是on Yarn跑。
离线计算平台特性:
目前42P+总存储量,每天有15万个Mapreduce和Spark任务,有2500+节点,支持3机房部署,数据库总共16K个数据表,复杂度还是比较高的。
3、数据管理体系
数据管理体系主要包括自研的调配系统,数据质量的监控,资源管理和任务审核以及开发配置中心等等,之后这些都会整合到整个的数据开放平台。
数据管理体系主要实现了这样几点功能,第一点是基于SQL解析做了ETL任务之间的自动解析。
基于资源预留的模式做了各业务线成本的核算,整体的资源大体是跑到Yarn上的,每个业务线会有一些承诺资源、保证资源,还可以弹性伸缩,里面会有一些预算。
工作的重点,对于关键性任务会注册SLA保障,并且包括数据内容质量,数据时效性内容都有一定的监控。
这是解析出来的依赖关系,红色的是展示的一条任务,有一系列的上游。这是我们的资源管理系统,可以分析细到每个任务每时每刻的资源使用,可以聚合,给每个业务线做成本核算。
这是对于数据质量管理中心,上面可以写一些简单的SQL,监控某一个表的数据结果是否符合我们业务的预期。下面是数据管理,就是我们刚刚提到的,对每个关键的数据表都有一些SLA的跟踪保障,会定期发日报,观察他们完成时间的一些变动。
4、关于BI产品
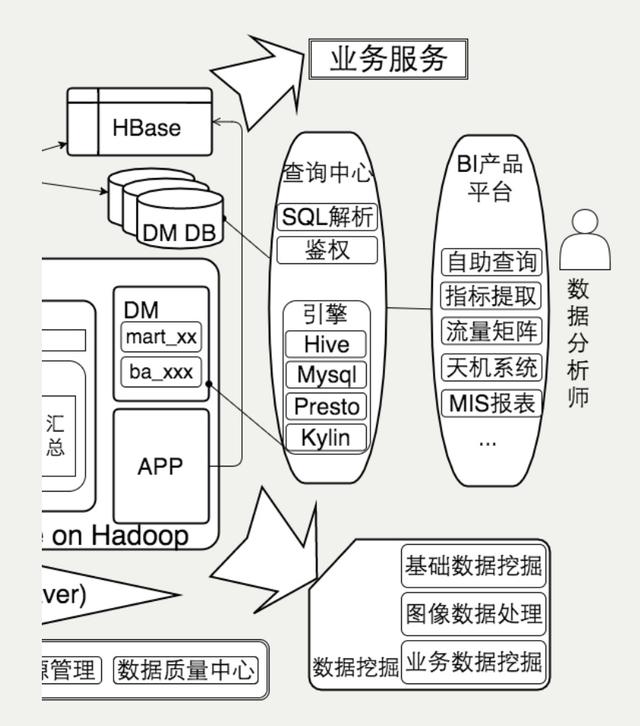
BI是基于数据应用平台化的场景。查询部分主要通过一个查询中心来支持,包括Hive,MySQL,Presto,Kylin等引擎,在查询中心里面我们做SQL解析。前面是一系列的BI产品,目前大部分是自研,面向用户可以直接写SQL的自主查询,并且看某一个指标,某一个时间段类似于online的分析数据产品,以及给BOSS们看的天机系统。
还有指标提取工具,和商用oneline前端分析引擎设计是比较类似的,选取维度范围,还有适时的计算口径,会有一系列对维度适时的管理。数据内容数据表不够,还会配一些dashboard。
在前端分析方面,我们开发了星空展示中心,可以基于前面指标提取结果,配置一系列的饼图、线图、柱状图,去拖拽,最后构建出一个dashboard,功能同市面上的其他BI产品如Tableau、FineBI类似。
二、平台演进时间线
1、平台发展
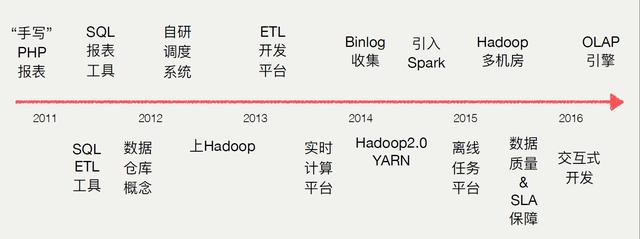
由于我在16年底就离开了美团,秉着负责的态度,只写我知道的
最开始美团开展数据这方面的工作的时候是2011年,当时的数据统计都是基于手写的报表,就是来一个需求我们基于线上数据建立一个报表页面,写一些表格。久而久之便跟不上管理模式了。首先是内部信息系统的工作状态,并不是一个垂直的,专门用做数据分析的平台,这个系统当时还是跟业务去共享的,跟业务的隔离非常弱,跟业务是强耦合的,而且每次来数据需求的时候都要有一些特殊的开发,开发周期非常长。
面对这个问题我们做了一个目前来看还算比较好的决策,就是重度依赖SQL。对SQL分装了一些报表工具,对SQL做了etl工具。主要是在SQL层面做一些模板化的工具,支持时间等变量。这个变量会有一些外部的参数传递进来,然后替换到SQL的行为。
在2011下半年,我们引入了整个数据仓库的概念,梳理了所有数据流,设计整个数据体系。做完了数据仓库整体的构建,发现整体的ETL被开发出来了。首先ETL都是有一定的依赖关系的,但是管理起来成本非常高,所以自研了一个系统。另外发现数据量越来越大,原来基于单机MySQL的数据解析是搞不定的,所以2012年上了四台Hadoop机器,后面十几台,到最后的几千台,目前可以支撑各个业务去使用。
2、最新进展
我们也做了一个非常重要的事就是ETL开发平台,原来都是基于Git仓库管理,管理成本非常高,当时跟个业务线已经开始建立自己数据开发的团队,我们把他们开发的整个流程平台化,各个业务线就可以自建。之后遇到的业务场景需求越来越多,特别是实时应用。2014年启动了实时计算平台,把原来原有关系型数据表全量同步模式,改为Binlog同步模式。我们也是在国内比较早的上了Hadoop2.0 on Yarn的改进版,好处是更好的激起了Spark的发展。另外还有Hadoop集群跨多机房,多集群部署的情况,还有OLAP保障,同步开发工具。
3、平台化思路总结
(1)平台的价值
作为一个平台的团队,核心价值其实就三个:
- 对于重复的事情要做精做专
- 统一化,可以推一些标准,推一些数据管理的模式,减少业务之间的对接成本
- 最重要的是为业务整体效率负责,包括开发效率、迭代效率、维护运维数据流程的效率,还有整个资源利用的效率
(2)平台的发展
如果才能发展成一个好的平台呢?
我理解的三点:
- 首先支持业务是第一位的,如果没有业务我们平台其实是没法继续发展的
- 第二是与先进业务同行,辅助并沉淀技术。在一个所谓平台化的公司,有多个业务线,甚至各个业务线已经是独立的情况下,必定有一些业务线是先行者,他们有很强的开发能力、调研能力,我们的目标是跟这些先行业务线同行
- 第三是设立规范,用积累的技术支撑后发业务。与业务一起前进的过程中,把一些经验、技术、方案、规范慢慢沉淀下来。对于刚刚新建的业务线,或者发展比较慢的业务线,我们基本策略是设置一系列的规范,跟优先先行业务线积累去支撑后续的业务线,以及功能开发的时候也可以借助,保持平台团队对业务的理解
(3)关于开源
以上谈到的平台中有很多是开源的直接拿来用的,比如说,zeppelin,Kylin。
我们的策略是持续关注,其实也是帮业务线做前瞻性调研,他们团队每天都在看数据,看新闻,他们会讲新出的一个项目你们怎么推,你们不推我们推了,我们可能需要持续关注,设计一系列的调研方案,帮助这些业务去调研,这样调研这个事情我们也是重复的事情只干一次。
如果有一些共性patch的事情,特别一些bug、问题内部也会有一个表共享,内部有大几十个patch。选择性的重构,最后才会大改,特别在选择的时候我们强调从业务需求出发,理智的进行选型权衡,最终拿出来的方案是靠谱能落地实施的方案。





