一文详解被阿里腾讯视作核心机密的大数据平台架构
文章来源:未知
作者:老客SEO
人气:15
 2019-11-07 10:16:34
2019-11-07 10:16:34
上一篇文章讲的是美团的大数据平台架构,相信大家也看到了这种平台的优势,也就是因为这种大数据平台架构的存在,阿里才会提出数据中台这么个非常好用的东西,后面有空会和大家再讲讲数据中台。
好了,言归正传,如果我们能够化整为零,在企业内部从宏观、整体的角度设计和实现一个统一的大数据平台,引入单一集群、单一存储,统一服务和统一安全的架构思想,就能很好的帮助企业解决很多问题。
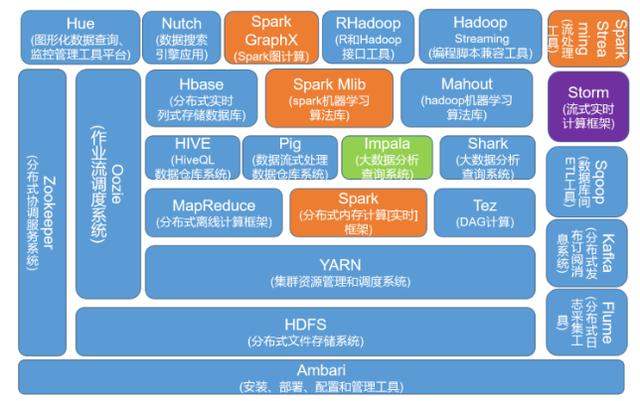
提到大数据分析平台,不得不说Hadoop系统,Hadoop到现在也超过10年的历史了,很多东西发生了变化,版本也从0.x进化到目前的2.6版本。我把2012年后定义成后Hadoop平台时代,这不是说不用Hadoop,而是像NoSQL (Not Only SQL)那样,有其他的选型补充。
大数据分析平台
Hadoop: 开源的数据分析平台,解决了大数据(大到一台计算机无法进行存储,一台计算机无法在要求的时间内进行处理)的可靠存储和处理。适合处理非结构化数据,包括HDFS,MapReduce基本组件。
HDFS:提供了一种跨服务器的弹性数据存储系统。
MapReduce:技术提供了感知数据位置的标准化处理流程:读取数据,对数据进行映射(Map),使用某个键值对数据进行重排,然后对数据进行化简(Reduce)得到最终的输出。
Amazon Elastic Map Reduce(EMR):托管的解决方案,运行在由Amazon Elastic Compute Cloud(EC2)和Simple Strorage Service(S3)组成的网络规模的基础设施之上。如果你需要一次性的或不常见的大数据处理,EMR可能会为你节省开支。但EMR是高度优化成与S3中的数据一起工作,会有较高的延时。Hadoop 还包含了一系列技术的扩展系统,这些技术主要包括了Sqoop、Flume、Hive、Pig、Mahout、Datafu和HUE等。
这里就不一一列举了,有很多,有感兴趣的可以和我私信讨论。
大数据平台架构
大数据计算通过将可执行的代码分发到大规模的服务器集群上进行分布式计算,以处理大规模的数据,即所谓的移动计算比移动数据更划算。但是这样的计算方式必然不会很快,即使一个规模不太大的数据集上的一次简单计算,MapReduce也可能需要几分钟,Spark快一点,也至少需要数秒的时间。
而网站处理用户请求,需要毫秒级的响应,也就是说,要在1秒内完成计算,大数据计算必然不能实现这样的响应要求。但是网站应用又需要使用大数据实现统计分析、数据挖掘、关联推荐、用户画像等一系列功能。
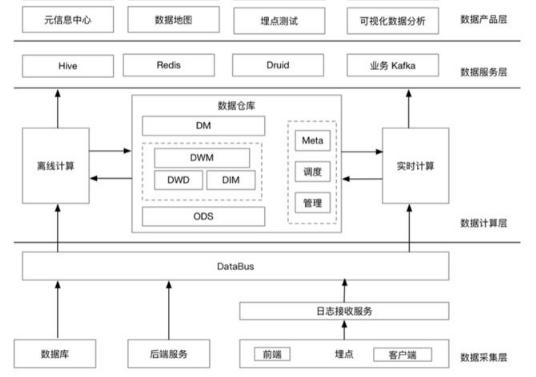
所以网站需要构建一个大数据平台,去整合网站应用和大数据系统之间的差异,将应用程序产生的数据导入到大数据系统,经过处理计算后再导出给应用程序使用。一个典型的网站大数据平台架构如下图:
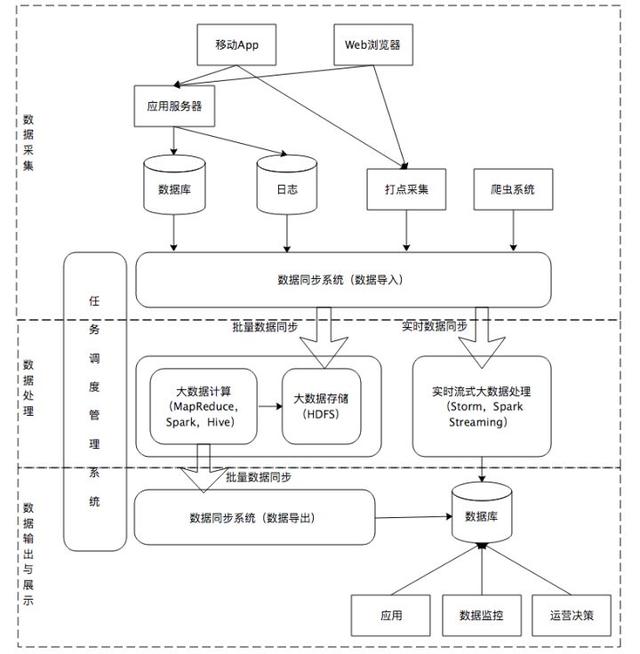
大数据平台可分为三个部分:
1.数据采集
将应用程序产生的数据和日志等同步到大数据系统中,由于数据源不同,这里的数据同步系统实际上是多个相关系统的组合。数据库同步通常用Sqoop,日志同步可以选择Flume,打点采集的数据经过格式化转换后通过Kafka传递。
不同的数据源产生的数据质量可能差别很大,数据库中的数据也许可以直接导入大数据系统就可以,而日志和爬虫产生的数据就需要进行大量的清洗、转化处理才能有效使用。所以数据同步系统实际上承担着传统数据仓库ETL的工作。
2.数据处理
这里是大数据存储与计算的核心,数据同步系统导入的数据存储在HDFS。MapReduce、Hive、Spark等计算任务读取HDFS上的数据进行计算,再将计算结果写入HDFS。
MapReduce、Hive、Spark等进行的计算处理被称作是离线计算,HDFS存储的数据被称为离线数据。相对的,用户实时请求需要计算的数据称为在线数据,这些数据由用户实时产生,进行实时在线计算,并把结果数据实时返回用户,这个计算过程中涉及的数据主要是用户自己一次请求产生和需要的数据,数据规模非常小,内存中一个线程上下文就可以处理。
在线数据完成和用户的交互后,被数据同步系统导入到大数据系统,这些数据就是离线数据,其上进行的计算通常针对(某一方面的)全体数据,比如针对所有订单进行商品的关联性挖掘,这时候数据规模非常大,需要较长的运行时间,这类计算就是离线计算。
除了离线计算,还有一些场景,数据规模也比较大,要求的处理时间也比较短。比如淘宝要统计每秒产生的订单数,以便进行监控和宣传。这种场景被称为大数据流式计算,通常用Storm、Spark Steaming等流式大数据引擎来完成,可以在秒级甚至毫秒级时间内完成计算。
3.数据输出与展示
大数据计算产生的数据还是写入到HDFS中,应用程序不可能到HDFS中读取数据,所以必须要将HDFS中的数据导出到数据库中。数据同步导出相对比较容易,计算产生的数据都比较规范,稍作处理就可以用Sqoop之类的系统导出到数据库。
这时,应用程序就可以直接访问数据库中的数据,实时展示给用户,比如展示给用户的关联推荐的商品。淘宝卖家的量子魔方之类的产品,其数据都来自大数据计算产生。
除了给用户访问提供数据,大数据还需要给运营和决策层提供各种统计报告,这些数据也写入数据库,被相应的后台系统访问。很多运营和管理人员,每天一上班,就是登录后台数据系统,查看前一天的数据报表,看业务是否正常。如果数据正常甚至上升,就可以稍微轻松一点,如果数据下跌,焦躁而忙碌的一天也马上就开始了。
将上面三个部分整合起来的是任务调度管理系统,不同的数据何时开始同步,各种MapReduce、Spark任务如何合理调度才能使资源利用最合理、等待的时间又不至于太久,临时的重要任务能够尽快执行,这些都需要任务调度管理系统完成。有时候对分析师和工程师开放的作业提交、进度跟踪,数据查看等功能也集成在这个系统中。
对于每个公司的大数据团队,最核心开发维护的也就是这个系统,大数据平台上的其他系统一般都有成熟的开源软件可以选择,作业调度管理会涉及很多个性化的需求,通常需要团队自己开发。
看到这里,你们对整个大数据平台架构了解了吗,如果还没有,我特地选了几个知名互联网公司的例子给你们,图片有点糊,谅解。
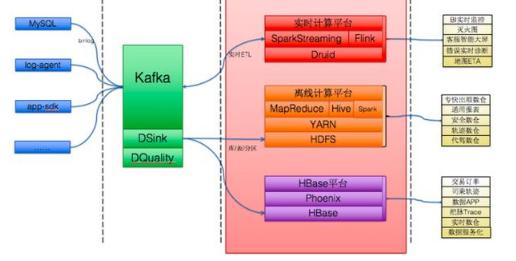
滴滴