百度开源自然语言理解模型 ERNIE 2.0,16 个 NLP 任务中碾压 BERT 和 XLNet!
文章来源:未知
作者:老客SEO
人气:15
 2019-08-04 22:07:05
2019-08-04 22:07:05

7 月 30 日,百度发布了 ERNIE(Enhanced Representation through kNowledge IntEgration)的优化版本——ERNIE 2.0 自然语言理解框架。这个中英文对话的 AI 框架不仅获得了最优的(SOTA)结果,并且在 16 个 NLP 任务中表现出优于 BERT 和最近的 XLNet 的高水准。目前,ERNIE 2.0 代码和英文预训练模型已开源。
ERNIE 2.0 的由来
近年来,类似于 BERT,XLNet 的无监督预训练自然语言表达模型在各种自然语言理解任务中取得了重大突破,包括语言推断、语义相似度、命名实体识别、情感分析等。这也表明了基于大规模数据的无监督预训练技术能够在自然语言处理中发挥至关重要的作用。
SOTA 预训练模型(如 BERT,XLNet 和 ERNIE 1.0)的预训练系统核心是基于几个简单的任务来模拟单词或句子的共现。例如,BERT 构建了掩码模型和下一个句子预测任务,从而捕获单词和句子的共现信息;XLNet 则构造了一种全排列的语言模型,并采用了自回归的方式来捕获单词的共现信息。
然而除了共现之外,训练语料库中还包含语法、语义信息等更多有价值的信息。例如:命名实体(名称、位置和组织),则可以包含概念信息、句子之间的顺序和距离关系等结构知识;而文档层面的语义相似性或句子之间的话语关系,则能够训练模型学习语义感知表示。假设模型能够经过训练从而不断学习更多类型的任务,是否这样可以进一步提高模型的效果呢?
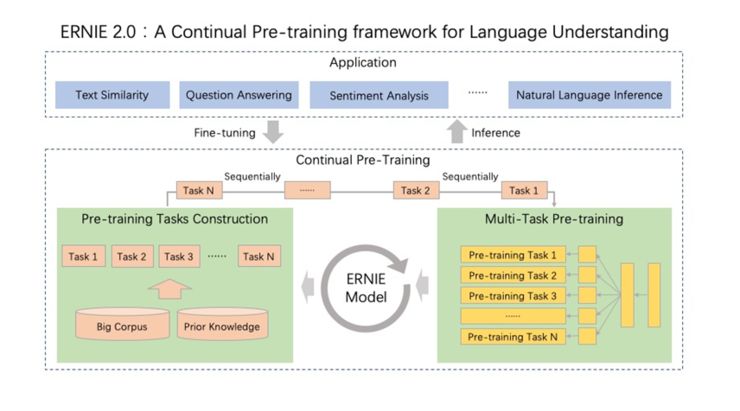
ERNIE 2.0 ——可持续学习语义理解框架
ERNIE 2.0 介绍
基于这一理念,百度提出了一种持续学习的语义理解预训练框架 ERNIE 2.0,它可以通过持续的多任务学习,逐步学习和建立预训练任务。
该框架支持增量引入词汇 (lexical)、语法 (syntactic) 、语义 (semantic) 等 3 个层次的自定义预训练任务,并通过多任务学习对其进行训练,实现全面捕捉训练语料中的词法、语法、语义等潜在信息。而且每当引入新任务时,该框架在递增地训练分布式表示的同时,还会记住先前任务的信息。
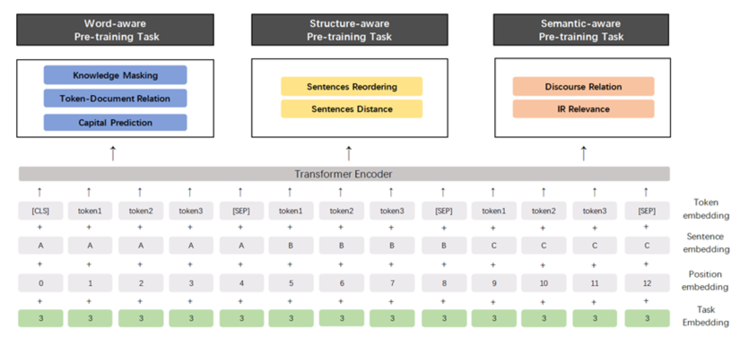
新发布的 ERNIE 2.0 模型的结构
ERNIE 2.0 与 BERT 或 XLNet 等经典预训练方法的不同之处在于,它并不是在少量的预训练任务上完成的,而是通过不断引入大量预训练任务,从而帮助模型高效地学习词汇、句法和语义表征。作为一种全新的语言理解持续预训练框架,ERNIE 2.0 不仅实现了 SOTA 效果,而且为开发人员构建自己的 NLP 模型提供了可行的方案。
ERNIE 2.0 测试效果
百度将 ERNIE 2.0 模型的性能与英文数据集 GLUE 和 9 个流行的中文数据集的现有 SOTA 预训练模型进行了比较。结果表明,ERNIE 2.0 在 7 种 GLUE 语言理解任务上优于 BERT 和 XLNet,并在所有 9 种中文 NLP 任务上击败 BERT,例如:基于 DuReader 数据集的阅读理解,情感分析和问答。
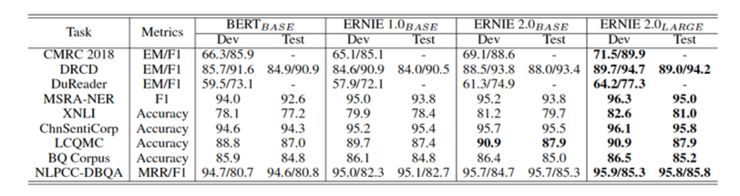
模型在 9 项常规中文 NLP 任务中的结果;模型结果均为五次实验结果的中位数,粗体字表示 SOTA 结果
实际上根据 GLUE 数据集的测试结果,无论是基本模型还是大型模型,我们能够观察到 ERNIE 2.0 在英语任务上优于 BERT 和 XLNET。此外,ERNIE 2.0 大型模型还实现了最佳性能,并为中文 NLP 任务创造了新的最优性能的结果。
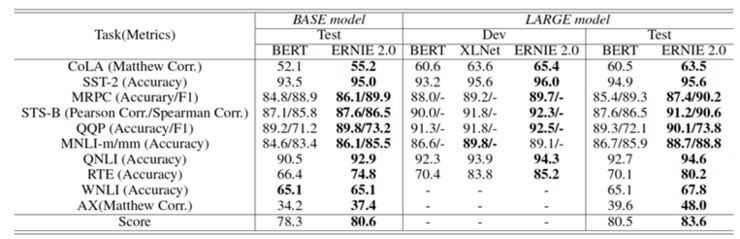
模型在 GLUE 上的结果,其中开发集上的结果是五次实验结果的中位数,测试集结果根据 GLUE 评估服务完成
原文地址:
http://research.baidu.com/Blog/index-view?id=121
模型论文地址:
https://arxiv.org/abs/1907.12412
Github 项目地址:
https://github.com/PaddlePaddle/ERNIE





