想要了解银行数据仓库,必须学会信用风险建模
文章来源:未知
作者:老客SEO
人气:20
 2019-11-07 10:33:29
2019-11-07 10:33:29
信用风险
银行的经营风险的机构,信用风险是银行经营的主要风险之一,它的管理好坏直接影响到银行的经营利润和稳定经营。信用风险是指交易对手未能履行约定契约中的义务而给银行造成经济损失的风险。
典型的表现形式包括借款人发生违约或信用等级下降。借款人因各种原因未能及时、足额偿还债务/银行贷款、未能履行合同义务而发生违约时,债权人或银行必将因为未能得到预期的收益而承担财务上的损失。
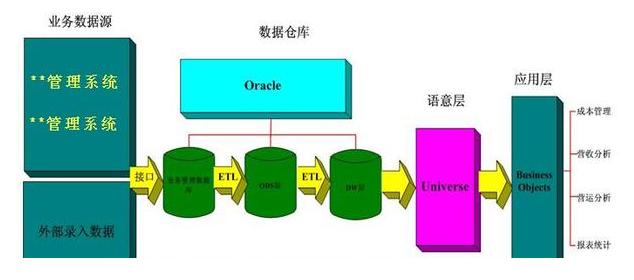
信用风险评估是银行数据仓库重要的一部分
那如何来表示某个交易对手的信用情况呢,一般使用信用等级或信用评分来来表示,等级越低或评分越低,发生违约的概率会增加。这个信用评分主要应用在客户的贷前和贷后管理中,贷前是指客户贷款申请阶段,银行受理客户贷款申请时会根据客户提交的信息、人行征信、其它数据源按一定的规则计算出一个违约概率和风险评分或信用等级。
再根据这个评分或评级来确定客户的授信额度和利率。计算出的评分或评级越高,违约概率越低,比如在进行个人贷前评分时主要关注以下5方面:
(1)People:贷款人状况,包括历史还款表现、当前负债情况、资金饥渴度等;
(2)Payment:还款来源,如基本收入、资产水平、月收支负债比、无担保总负债等;
(3)Purpose:资金用途,如消费、买房,需要规避贷款资金用于投资或投机性质较高领域,如股票和数字货币;
(4)Protection:债权确保,主要是看是否有抵押物或担保,需要看抵押物用途、质量、价格等关键要素;
(5)Perspective:借款户展望,从地域、行业、人生阶段等考察稳定性及潜力;
贷后是指客户借款后银行持续跟进客户的信用情况,如果发现信用评分降低或者某些指标达到风险预警指标的阈值,说明风险升高,则会进行冻结额度甚至提前进行贷款收回。特别是对于逾期客户。
风险建模步骤
在进行信用评估时如何选择客户属性、如何确定评分或评级规则呢?这就需要进行风险建模,通过分析历史数据来确定哪些特征或指标对客户的违约相关性大,可以了解客户的还款能力以及还款意愿。并通过一定方法来建立评分和评级的规则。那风险建模主要分为以下步骤:

(1)业务理解:
主要评估当前现状、确定业务目标,选择建模方法,比如需要进行XX贷款产品的贷前评分模型并确定准入规则,建模方式比如为评分卡,评分应用为基于评分确定贷款准入规则以及额度和利率规则,同时需要确定分析数据的好客户和坏客户标准,如逾期90天以上为坏客户;
(2)数据理解:
首先需要准备建模的样本数据,如抽取近2年的获得类似产品的客户相关信息以及根据好客户和坏客户标准确定的结果。并针对业务数据进行业务含义理解、对数据进行收集、探索,了解每个变量的数据质量、缺失情况,数据分布等。
比如对于客户在人行的征信数据、客户在银行的存款、理财等信息、以及客户申请填写的家庭、房产信息、外部获得的客户教育、司法等相关信息进行业务理解和数据分布、质量的探索,对缺失值比例过大的变量或准确性不高的变量进行剔除,同时也要确定对于样本数据中哪些数据进行建模,哪些数据进行验证。
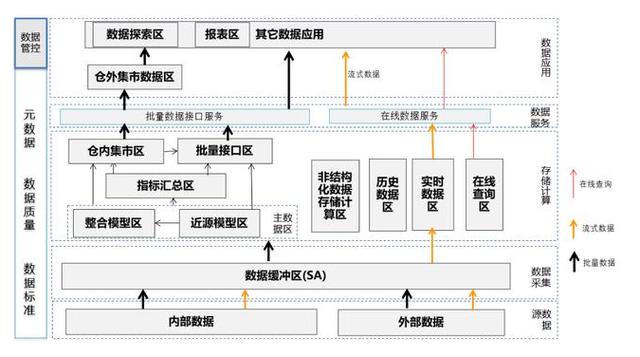
(3)数据准备:
主要对数据进行预处理和指标加工,指标加工指基于基础数据进行指标加工,如最近1个月的征信查询次数,最近1年的逾期次数等,数据预处理主要工作包括对每一个变量进行数据清洗、缺失值处理、异常值处理、数据标准化等,主要目的是将获取的原始数据转变成可用于建模的结构化数据。
比如对于连续变量,就是要寻找合适的切割点把变量分为几个区间段以使其具有最强的预测能力,也称为“分箱”。例如客户年龄就是连续变量,在这一步就是要研究分成几组、每组切割点在哪里预测能力是最强的。分箱的方法有等宽、等频、聚类(k-means)、卡方分箱法、单变量决策树算法(ID3、C4.5、CART)、IV最大化分箱法、best-ks分箱法等。如果是离散变量,每个变量值都有一定的预测能力,但是考虑到可能几个变量值有相近的预测能力,因此也需要进行分组。
通过对变量的分割、分组和合并转换,分析每个变量对于结果的相关性,剔除掉预测能力较弱的变量,筛选出符合实际业务需求、具有较强预测能力的变量。检测变量预测能力的方法有:WOE(weight of Evidence) 、IV(informationvalue)等。
(4)分析建模:
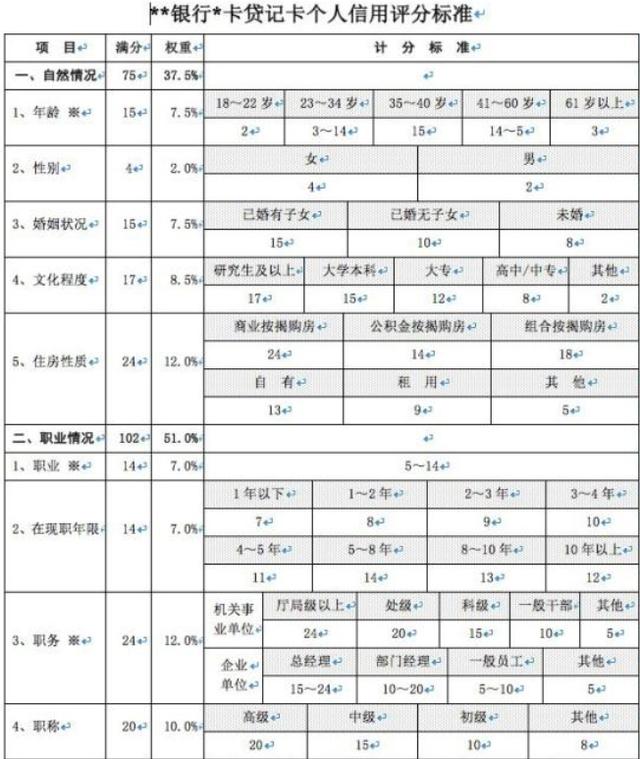
即对于筛选出来的变量以及完成好坏定义的样本结果。放入模型进行拟合。如评分卡一般采用常见的逻辑回归的模型,PYTHON、SAS、R都有相关的函数实现模型拟合。以下是生成的评分卡的例子。

(5)评估及报告:
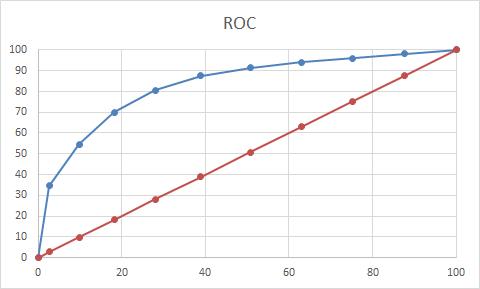
即通过验证样本对模型的预测进行校验。评估模型的准确性和稳健性,并得出分析报告。常用的方法有ROC曲线、lift提升指数、KS(Kolmogorov-Smirnov)曲线、GINI系数等。
(6)应用:
对模型进行实际部署和应用,如基于评分进行客户准入和产生额度,并在贷款系统进行模型部署,自动对申请客户进行评分。
(7)监测:
建立多种报表对模型的有效性、稳定性进行监测,如稳定性监控报表来比较新申请客户与开发样本客户的分值分布,不良贷款分析报表来评估不同分数段的不良贷款,并且与开发时的预测进行比较,监控客户信贷质量。随着时间的推移和环境变化,评分模型的预测力会减弱,所以需要持续监控并进行适当调整或重建。
在信用风险建模中,目前评分卡建模还是主要的方式,除了申请评分(A卡(Application score card))还有B卡(Behavior score card)行为评分卡、C卡(Collection score card)催收评分卡。B卡主要进行客户贷后管理,如何进行风险预警,C卡进行催收管理,确定如何催收以及催收方式和时间点。
信用风险模型中还有一个是反欺诈模型,它主要是识别假冒身份、虚假信息、批量薅羊毛等欺诈行为。随着机器学习和大数据的发展,其它的一些建模方式如决策树、深度神经网络也越来越多的应用到了风险建模中。
总结
信用风险模型是数据仓库支持的重要数据应用之一,在风险建模分析阶段,数据仓库是建模样本数据以及衍生指标加工的主要提供者,业务人员一般在自助分析平台进行数据分析和建模,模型建立完成并部署后,会基于数据仓库数据进行模型效果的监控。
在贷后管理中,风险集市也会进行贷后指标的加工。另外风险模型以及预警中会经常使用到外部数据,这部分数据也是通过数据仓库进行对接、加工和存储。
相关文章
-
出去千万别说UI和美工是一个职业,千万别暴露你的缺点哦
文章来源:老铁商城2019-10-31 -
我优化多年的 C 语言竟然被 80行Haskell 打败了?
文章来源:老铁商城2019-10-20 -
当程序员遇到中秋节,会产生怎样的化学反应......
文章来源:老铁商城2019-09-18 -
淘宝、京东这些网站的哪个部分用了web前端技术?你能学会吗?
文章来源:老铁商城2019-09-18 -
Linux和哪些行业有关?2019Linux运维必备哪些技能?
文章来源:老铁商城2019-09-18 -
公认最具影响力的4种编程语言!平均薪资20K,Java第一
文章来源:老铁商城2019-09-18 -
PYPL 9 月编程排行榜:Python第一,继续称霸!就业薪资怎么样?
文章来源:老铁商城2019-09-18





